One of the things I tend to avoid doing in R, partly because there are better tools elsewhere, is screenscraping. With the release of the new rvest package, I thought I’d have a go at what amounts to one of the simplest webscraping activites – grabbing HTML tables out of webpages.
The tables I had in my sights (when I can actually find them…) are the tables that appear on the newly designed FIA website that describe a range of timing results for F1 qualifying and races [quali example, race example].
Inspecting an example target web page, whilst a menu allows you to select several different results tables, a quick look at the underlying HTML source code reveals that all the tables relevant to the session (that is, a particular race, or complete qualifying session) are described within a single page.
So how can we grab those tables down from a target page? The following recipe seems to do the trick:
#install.packages("rvest")
library(rvest)
#URL of the HTML webpage we want to scrape
url="http://www.fia.com/events/formula-1-world-championship/season-2015/qualifying-classification"
fiaTableGrabber=function(url,num){
#Grab the page
hh=html(url)
#Parse HTML
cc=html_nodes(hh, xpath = "//table")[[num]] %>% html_table(fill=TRUE)
#TO DO - extract table name
#Set the column names
colnames(cc) = cc[1, ]
#Drop all NA column
cc=Filter(function(x)!all(is.na(x)), cc[-1,])
#Fill blanks with NA
cc=apply(cc, 2, function(x) gsub("^$|^ $", NA, x))
#would the dataframe cast handle the NA?
as.data.frame(cc)
}
#Usage:
#NUM:
## Qualifying:
### 1 CLASSIFICATION
### 2 BEST SECTOR TIMES
### 3 SPEED TRAP
### 4 MAXIMUM SPEEDS
##Race:
### 1 CLASSIFICATION
### 2 FASTEST LAPS
### 3 BEST SECTOR TIMES
### 4 SPEED TRAP
### 5 MAXIMUM SPEEDS
### 6 PIT STOPS
xx=fiaTableGrabber(url,NUM)
The fiaTableGrabber() grabs a particular table from a page with a particular URL (I really should grab the page separately and then extract whatever table from the fetched page, or at least cache the page (unless there is a cacheing option built-in?)
Depending on the table grabbed, we may then need to tidy it up. I hacked together a few sketch functions that tidy up (and remap) column names, convert “natural times” in minutes and seconds to seconds equivalent, and in the case of the race pits data, separate out two tables that get merged into one.
#1Q
fiaQualiClassTidy=function(xx){
for (q in c('Q1','Q2','Q3')){
cn=paste(q,'time',sep='')
xx[cn]=apply(xx[q],1,timeInS)
}
xx=dplyr:::rename(xx, Q1_laps=LAPS)
xx=dplyr:::rename(xx, Q2_laps=LAPS.1)
xx=dplyr:::rename(xx, Q3_laps=LAPS.2)
xx
}
#2Q, 3R
fiaSectorTidy=function(xx){
colnames(xx)=c('pos',
's1_driver','s1_nattime',
's2_driver','s2_nattime',
's3_driver','s3_nattime')
for (s in c('s1','s2','s3')) {
sn=paste(s,'_time',sep='')
sm=paste(s,'_nattime',sep='')
xx[sn]=apply(xx[sm],1,timeInS)
}
xx[-1,]
}
#3Q, 4R
fiaTrapTidy=function(xx){
xx
}
# 4Q, 5R
fiaSpeedTidy=function(xx){
colnames(xx)=c('pos',
'inter1_driver','inter1_speed',
'inter2_driver','inter2_speed',
'inter3_driver','inter3_speed')
xx[-1,]
}
# 2R
fiaRaceFastlapTidy=function(xx){
xx['time']=apply(xx['LAP TIME'],1,timeInS)
xx
}
# 6R
fiaPitsSummary=function(xx){
r=which(xx['NO']=='RACE - PIT STOP - DETAIL')
xx['tot_time']=apply(xx['TOTAL TIME'],1,timeInS)
Filter(function(x)!all(is.na(x)), xx[1:r-1,])
}
#6R
fiaPitsDetail=function(xx){
colnames(xx)=c('NO','DRIVER','LAP','TIME','STOP','NAT DURATION','TOTAL TIME')
xx['tot_time']=apply(xx['TOTAL TIME'],1,timeInS)
xx['duration']=apply(xx['NAT DURATION'],1,timeInS)
r=which(xx['NO']=='RACE - PIT STOP - DETAIL')
xx=xx[r+2:nrow(xx),]
#Remove blank row - http://stackoverflow.com/a/6437778/454773
xx[rowSums(is.na(xx)) != ncol(xx),]
}
So for example:
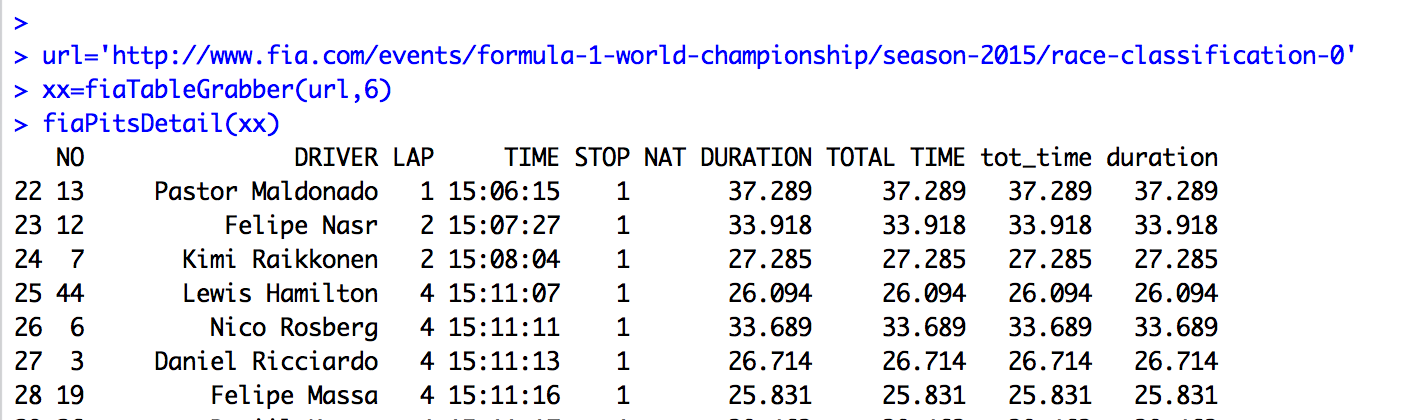
I’m still not convinced that R is the most natural, efficient, elegant or expressive language for scraping with, though…
PS In passing, I note the release of the readxl Excel reading library (no external-to-R dependencies, compatible with various flavours of Excel spreadsheet).
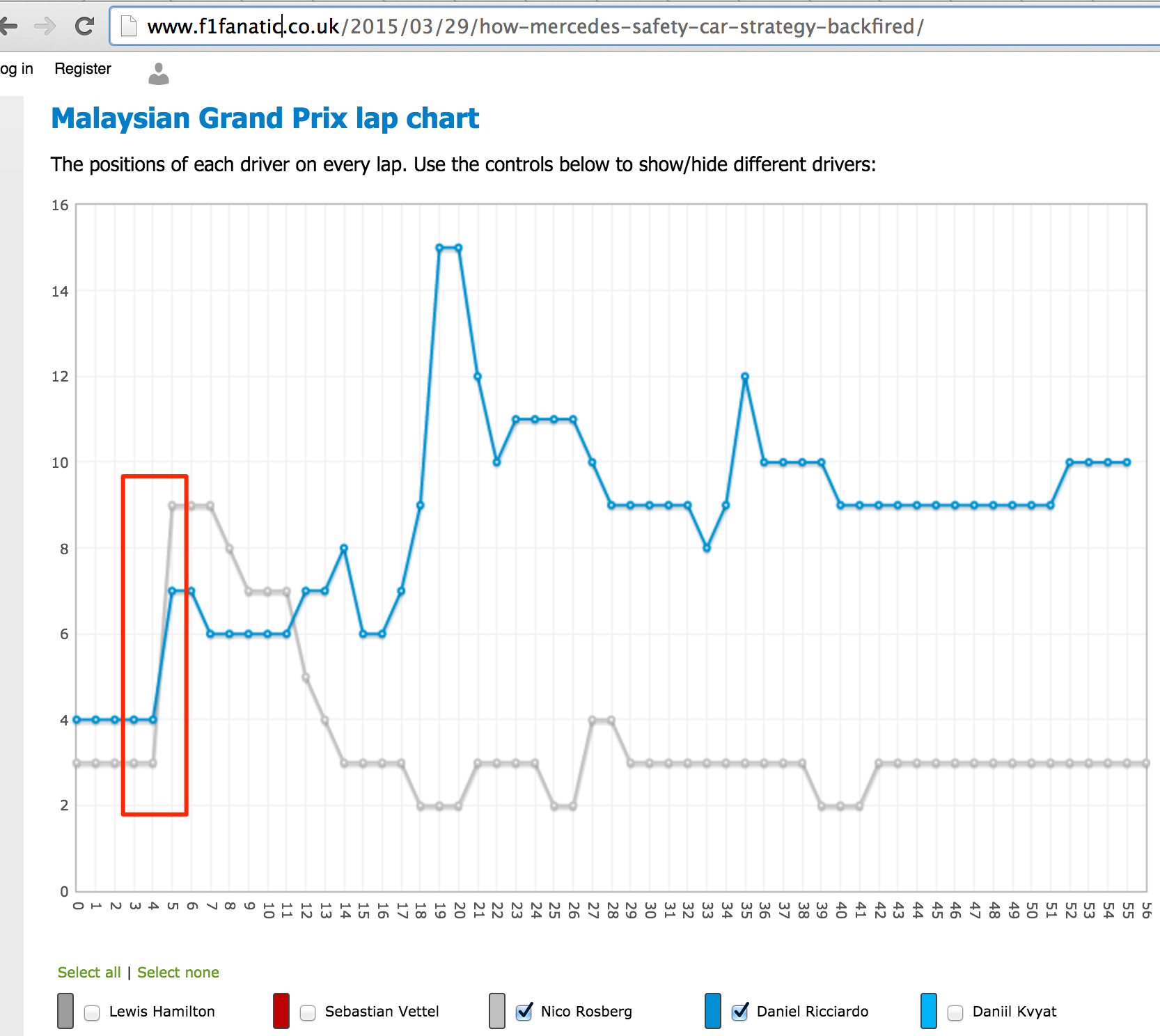
PPS Looking at the above screenshot, it strikes me that if we look at the time of day of and the duration, we can tell if there is a track position (at least) change in the pits… So for example, ROS goes in at 15:11:11 with a 33.689 stop and RIC goes in at 15:11:13 with a 26.714. So ROS enters the pits ahead of RIC and leaves after him? The following lap chart from f1fanatic perhaps reinforces this view?

Another option which I’ve used for several years is readHTMLTable() in the XML package. It generates a list of data frames, one per table. Doesn’t always get the parsing exactly right but generally easy to clean up.
Ah, handy – thanks… (I still far prefer Python for scraping though… much of the time the data I’m after isn’t in a table, or, if it is, horrible things have often been done to it!;-)
I used to do a lot of scraping using nokogiri (being a Ruby guy). But once I (sort of) got my head around XPath, I found I could do more in R. There’s xpathSApply() for example, also in the XML package.
I guess I’m just happier hacking code in py…
Yes I too have used R for automated scraping. I use it for collecting periodic data and updating it frequently. I you have a lot a page to visit, then it becomes sensible to add something that allows you to retry if there was a connection time-out or some other page related error.
I use a simple poor man’s solution for that.
I also make use of the html_nodes() function in the Rvest library to collect tabular data.
url.page <- url
u <- try(html(url.page))
while (class(u)[1] == "try-error"){
print("Retry")
Sys.sleep(1)
u <- try(html(url.page))
}
data %
html_nodes(“table”) %>%
.[[43]] %>%
html_table(fill=TRUE)
write.csv(data,sprintf(‘…_%04.f.csv’),page),row.names = FALSE)
I am beginer. can u explain me this line (after [[num]]. I can not make it to work
html_nodes(hh, xpath = "//table")[[num]] %>% html_table(fill=TRUE)
The %>% is the pipe operator, loaded in via magrittr (http://blog.revolutionanalytics.com/2014/07/magrittr-simplifying-r-code-with-pipes.html) which is itself loaded in via rvest. It passes the output of the bit on the left of the operator in as the first argument to the thing on the right.
Now it is clear. I was confused with “>” but it means “>” is int it?
readHTMLTable() in the XML package. then just see which is the biggest table.
I’d love to see an example with this data:
http://services.datasport.com/2015/zkb/winterthur/RANG091.HTM
it is just a “pseudo-table”, and – names aside – each row holds its data in plain strings.
The only way I saw, was to scrape it as a string:
doc <- html(as.character(address))
presect <- html_nodes(doc, "font")
tt <- html_text(presect[[3]])
tt <- gsub("#", "'", tt) # replace disruptive character
and then playing around with fixed width to get a proper data.frame:
w <- c(6, 26, 6, 25, 34, 10, 12, 8, 5, 15, 4, 1, 11)
df <- read.fwf(textConnection(tt), w, col.names=c("Rang","Name","Jg","Ort","Club","Zeit","zurück","bib","Kat","KRang","Pace","XX","Punkte"))
df <- df[-dim(df)[1],] # getting rid of "|"-column
df <- df[,-12]
I'd really would like to have a better way, i.e. without fixed widths.
The fixed width route would be the way I’d approach it as a first path. Another way might be to do s/thing like:
#get the preformatted text
txt=html_text(html_nodes(pp, xpath = “//pre”)[[1]])
#hack a dataframe with a single col
df=as.data.frame(strsplit(txt),’\r\n’))
Then use something like strsplit(txt,’ +’,) (two or more spaces) to split each “row”, though some sort of hack will be required to come with rows with the missing team name?. This approach also requires another split on the date col where date and city are only separated by a single space? Actually, the tidyr function ‘separate()’ might be better for splitting the column?
Perhaps craft a regex that will parse each line properly? The following is a first, literal attempt (I may have counted the columns wrong!)
str_match(txt, ‘*([0-9]*).(.*) *([0-9]{4}) +(.*) ([^ ]+) +([^ ]+) +([^ ]+) +([^ ]+) +([^ ]+) +([^ ]*)¦ +(.*)’)
Thank you for your hints!
So I have to realize this isn’t a problem about rvest (there is no easier way to collect the data in the first place). It is just a problem about handling Strings…
Also nice to know you’d chosen the fixed-widhts approach too – so I am not totally off.
Thank you again – I’ll tinker a bit with some of your suggestions (I am not a regex-wizard…)!