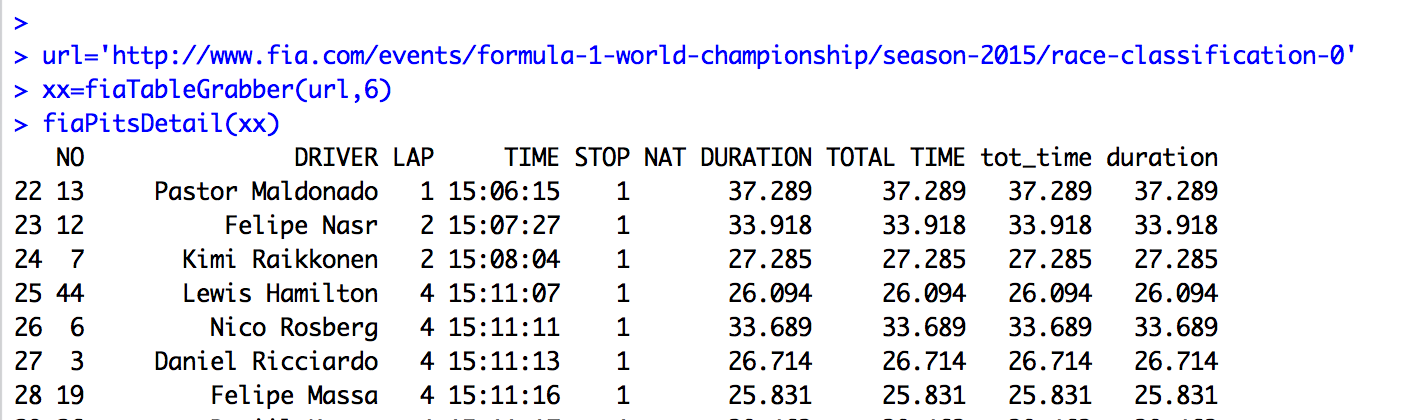
If charts are pictures, and every picture not only tells a story, but also saves a thousand words in doing so, how then are we to actually read them?
Take the following example, a quick #f1datajunkie sketch show how the Bahrain 2015 qualifying session progressed. The chart is split into three, one for each part of qualifying (which we might refer to as fractional sessions), which already starts to set the scene for the story. The horizontal x-axis is the time in seconds into qualifying at which each laptime is recorded, indexed against the first laptime recorded in qualifying overall. The vertical y-axis records laptimes in in seconds, limited to 107% of the fastest laptime recorded in a particular session. The green colour denotes a driver’s fastest laptime recorded in each fractional session, purple the overall fasted laptime recorded so far in a fractional session (purple trumps green). So again, the chart is starting to paint a picture.

An example of the sort of analysis that can be provided for a qualifying session can be found in a post by Justin Hynes, Lewis Hamilton seals his first Bahrain pole but Vettel poses the menace to Mercedes’ hopes, that appeared on he James Allen on F1 blog. In this post, I’ll try to match elements of that analysis with things we can directly see in the chart above…
[Hamilton] finish[ed] 0.411s clear of Ferrari’s Sebastian Vettel and more than half a second in front of his Mercedes team-mate Nico Rosberg
We don’t get the time gap exactly from the chart, but looking to the rightmost panel (Q3), finding the lowest vertical marks for HAM, VET and ROS, and imagining a horizontal line across to the y-axis, we get a feeling for the relative gaps.
Q1 got underway in slightly calmer conditions than blustery FP3 and Raikkonen was the first to take to the track, with Bottas joining the fray soon after. The Williams driver quickly took P1 but was then eclipsed by Rosberg, who set a time of 1: 35.657 on the medium tyres.
Q1 is the leftmost panel, in which we see RAI setting the first representative laptime at least (within the 107% limit of the session best overall), followed by BOT and then ROS improving on the early purple times.
The Mercedes man was soon joined in the top five by soft-tyre runners Nico Hulkenberg and Felipe Nasr.
HUL and NAS appear around the 300 cuml (cumulative laptime) mark. We note that PER is there in the mix too, but is not mentioned explicitly in the report.
In the closing stages of the session those in the danger zone were Max Verstappen, Pastor Maldonado and Will Stevens and Roberto Merhi.
On the right hand side of the chart, we see laps at the end of the session from MAL and VES (and way off the pace, STE). One problem with the chart as style above (showing cumulative best times in the session, makes it hard to see which a driver’s best session time overall actually is. (We could address this by perhaps displaying a driver’s session best time using a bold font.) The chart is also very cluttered around the cutoff time which makes it hard to see clearly who got through and who didn’t. And we don’t really know where the danger zone is because we have no clear indication of what the best 15 drivers’ times are – and hence, where the evolving cut-off time is…
Verstappen found the required pace and scraped into Q2 with a time of 1:35.611. Maldonado, however, failed to make it through, his best lap of 1:35.677 only being good enough for P16.
Verstappen’s leap to safety also pushed out Daniil Kvyat, with the Russian putting in a disappointing final lap that netted him P17 behind the Lotus driver. Hulkenberg was the last man through to Q2, the Force India driver’s 1:35.653 seeing him safely through with just two hundredths of a second in hand over Maldonado…
With an evolution of the cutoff time, and a zoom around the final cutoff time, we should be able to see what went on rather more clearly.
At the top of the order, Hamilton was quickest, finishing a tenth in front of Bottas. Rosberg was third, though he finished the session close on half a second down on his team-mate.
Felipe Massa was fourth for Williams, ahead of Raikkonen, Red Bull’s Daniel Ricciardo and Sebastian Vettel, who completed just three laps in the opening session. All drivers set their best times on the soft tyre.
This information can be quite clearly seen on the chart – aside from the tyre data which is not made available by the FIA.
The follow description of Q2 provides quite a straightforward reading of the second panel of the chart.
In the second session, Rosberg initially set the pace but Hamilton quickly worked his way back to the top of the order, his first run netting a time of 1:32.669. Rosberg was also again eclipsed by Massa who set a time three tenths of a second quicker than Rosberg’s.
The last to set an opening time were the Ferraris of Raikkonen and Vettel, though both rapidly staked a claim on a Q3 berth with the Finn in P2 and the German in P4.
Most of the front runners opted to rely on their first run to see them through and in the closing stages those in the drop zone were Hulkenberg, Force India team-mate Sergio Perez, Nasr, Sauber team-mate Ericsson and McLaren’s Fernando Alonso.
However, the chart does not clearly show how ROS’ early purple time was challenged by BOT, or how MAS early pace time was challenged mid-way through the session by VET and RAI.
Hulkenberg was the man to make the big move, claiming ninth place in Q2 with a time of 1:34.613. Behind him Toro Rosso’s Carlos Sainz scraped through in P10, six hundredths of a second clear of 11th-placed Sergio Perez. The Mexican was followed by Nasr and Ericsson. Alonso claimed P14, while 15th place went to the unfortunate Verstappen, who early in the session had reported that he was down on power.
Again, this reading of the chart would be aided by an evolving cut-off time line.
Looking now to the third panel…
The first runs in Q3 saw Hamilton in charge again, with the champion setting a time of 1:33.552 on used softs to take P1 three tenths of a second ahead of Red Bull’s Ricciardo, who prior to Hamilton’s lap had claimed the fastest S3 time of the session using new soft tyres.
Rosberg, also on used softs, was third, four thousandths of a second down on the Australian’s time. Hulkenberg, with just one new set of softs at his disposal, opted to sit out the first run.
The chart clearly shows the early and late session runs, and is reflected in the analysis:
In the final runs, Vettel was the first of the likely front-row men across the line and with purple times in S1 and S2, the German set a provisional pole time of 1:32.982. It was a superb lap but Hamilton was already running faster, stealing the S1 purple time from the German.
Ahead of the champion on track, Rosberg had similarly taken the best S2 time but he could not find more pace and when he crossed the line he slotted into third, four hundredths [??] of a second behind Vettel.
So what does Justin Hynes’ qualifying session commentary tell us about how we might be able to read the charted summary of the session? And how can we improve the chart to help draw out some of the stories? A couple of things jump out for me – firstly, the evolving purple and green times can be confusing, and are perhaps better placed (for a summary reading of the session) by best in session purple/green times; secondly, the evolution of the cut-off times would help to work out where drivers were placed at different stages of qualifying and what they still had to do – or whether a best-time-so-far recorded by a driver earlier in the session was bumped by the cutoff evolution. Note that the purple time evolution is identified implicitly by the lower envelope of the laptimes in each session.