Via a round-up post from Matt Jukes/@jukesie (Interesting elsewhere: Bring on the Bots), I was prompted to look again at Slack. OnTheWight’s Simon Perry originally tried to hook me in to Slack, but I didn’t need another place to go to check messages. Simon had also mentioned, in passing, how it would be nice to be able to get data alerts into Slack, but I’d not really followed it through, until the weekend, when I read again @jukesie’s comment that “what I love most about it [Slack] is the way it makes building simple, but useful (or at least funny), bots a breeze.”
After a couple of aborted attempts, I found a couple of python libraries to wrap the Slack API: pyslack and python-rtmbot (the latter also requires python-slackclient).
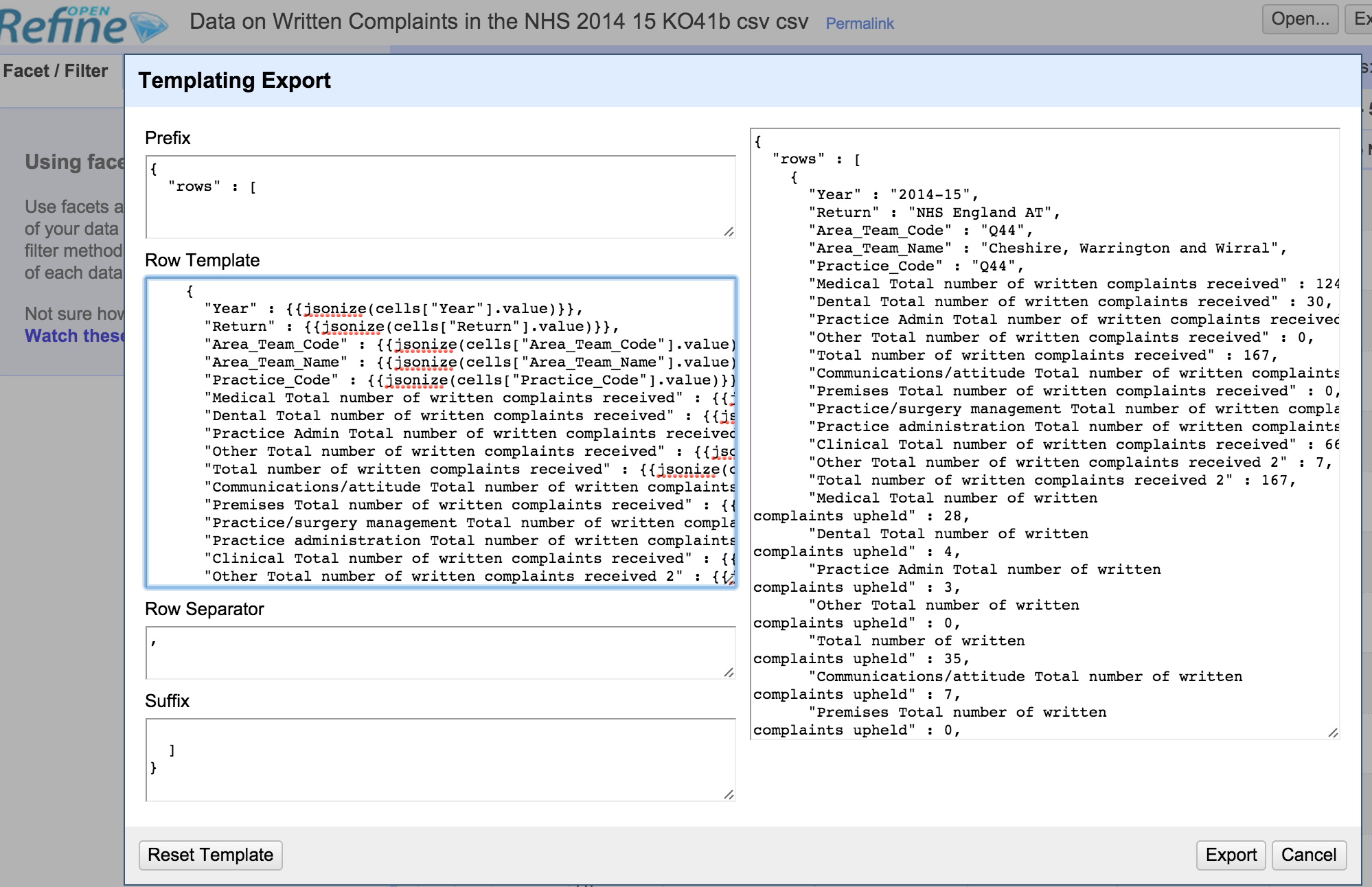
Using pyslack to send a message to Slack was pretty much a one-liner:
#Create API token at https://api.slack.com/web
token='xoxp-????????'
#!pip install pyslack
import slack
import slack.chat
slack.api_token = token
slack.chat.post_message('#general', 'Hello world', username='testbot')

I was quite keen to see how easy it would be to reuse one of more of my data2text sketches as the basis for an autoresponder that could get accept a local data request from a Slack user and provide a localised data response using data from a national dataset.
I opted for a JSA (Jobseekers Allowance) textualiser (as used by OnTheWight and reported here: Isle of Wight innovates in a new area of Journalism and also in this journalism.co.uk piece: How On The Wight is experimenting with automation in news) that I seem to have bundled up into a small module, which would let me request JSA figures for a council based on a council identifier. My JSA textualiser module has a couple of demos hardwired into it (one for the Isle of Wight, one for the UK) so I could easily call on those.
To put together an autoresponder, I used the python-rtmbot, putting the botcode folder into a plugins folder in the python-rtmbot code directory.
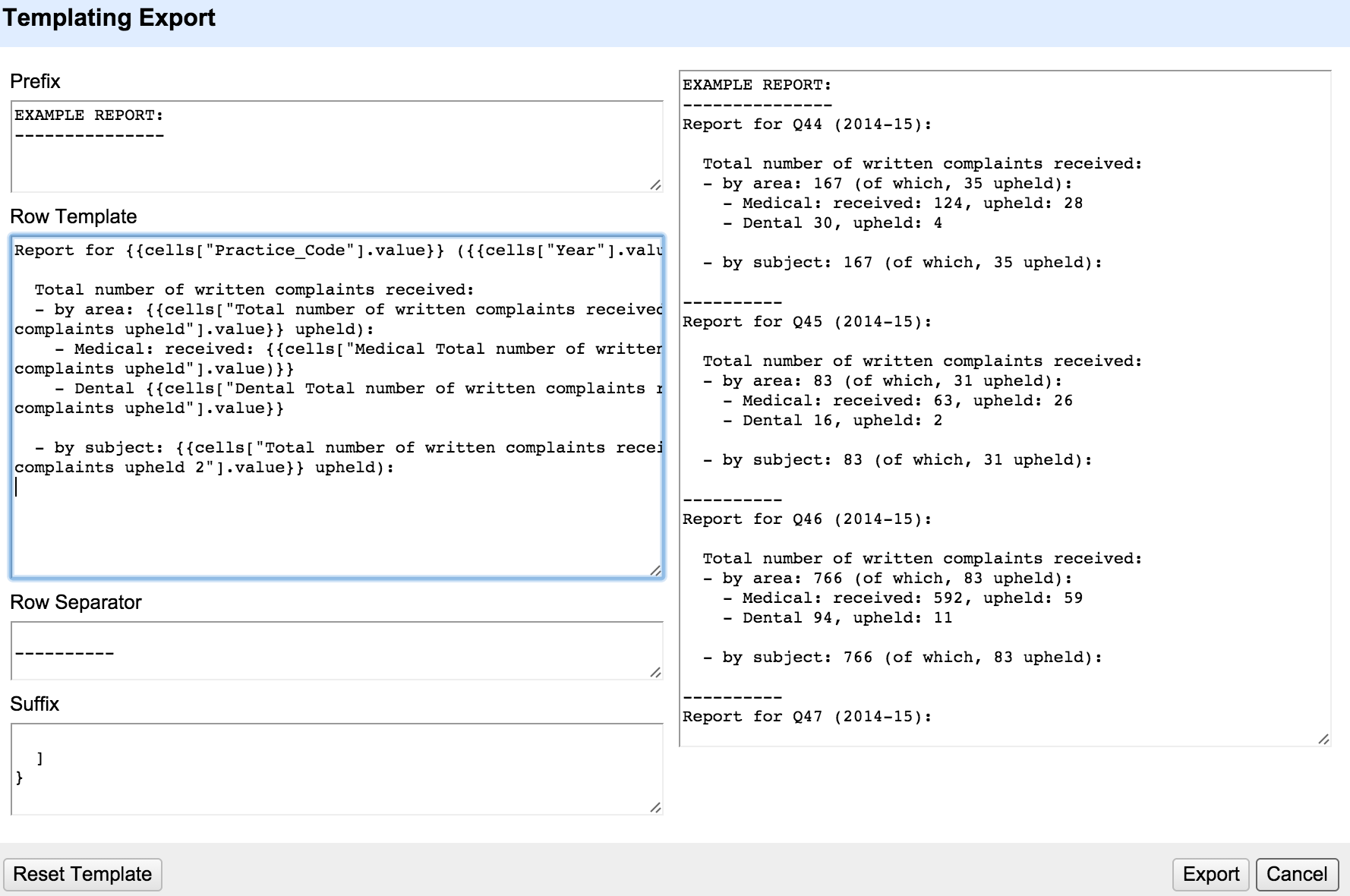
The code for the bot is simple enough:
from nomis import *
import nomis_textualiser as nt
import pandas as pd
nomis=NOMIS_CONFIG()
import time
crontable = []
outputs = []
def process_message(data):
text = data["text"]
if text.startswith("JSA report"):
if 'IW' in text: outputs.append([data['channel'], nt.otw_rep1(nt.iwCode)])
elif 'UK' in text: outputs.append([data['channel'], nt.otw_rep1(nt.ukCode)])
if text.startswith("JSA rate"):
if 'IW' in text: outputs.append([data['channel'], nt.rateGetter(nt.iwCode)])
elif 'UK' in text: outputs.append([data['channel'], nt.rateGetter(nt.ukCode)])

Rooting around, I also found a demo I’d put together for automatically looking up a council code from a Johnston Press newspaper title using a lookup table I’d put together at some point (I don’t remember how!).
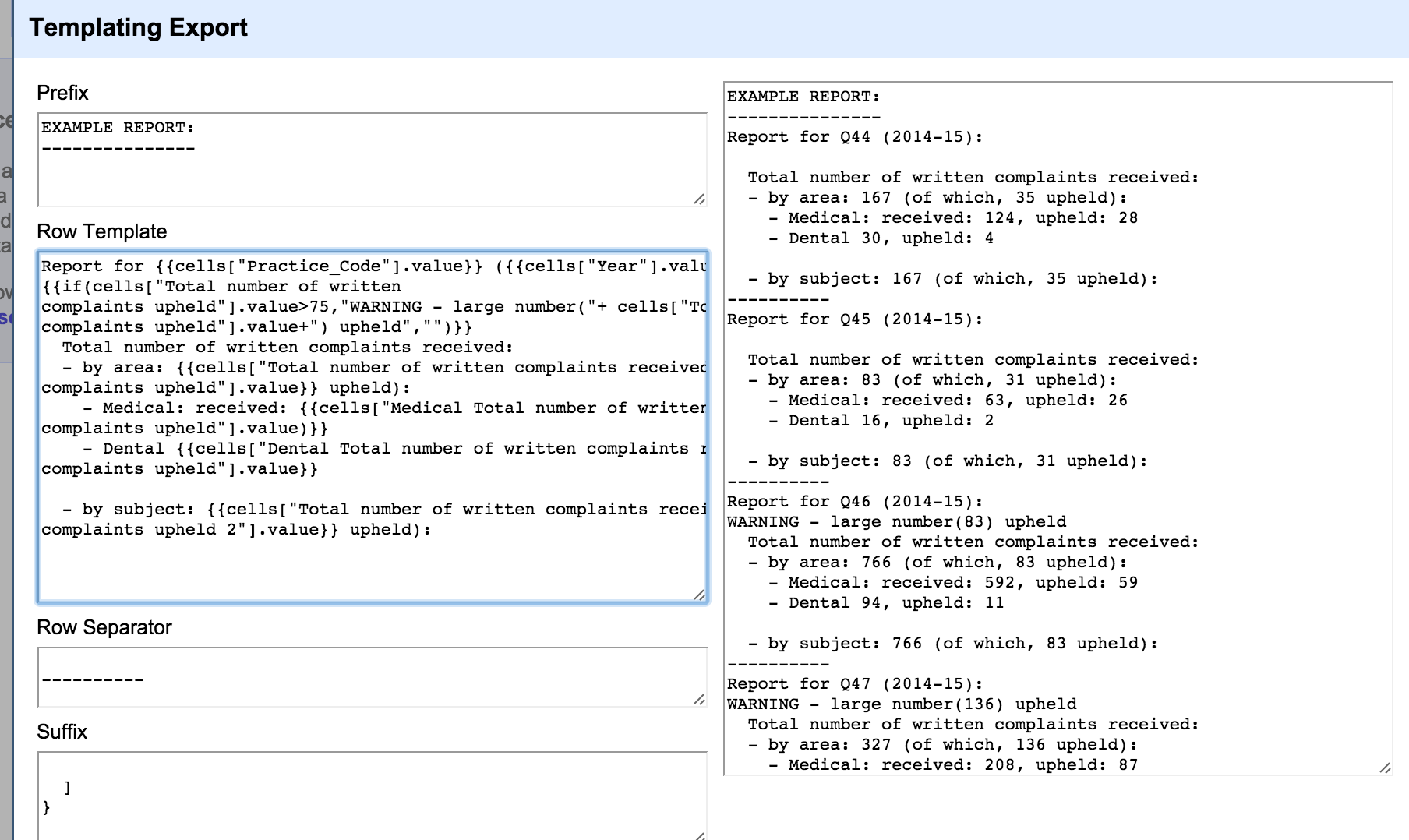
Which meant that by using just a tiny dab of glue I could extend the bot further to include a lookup of JSA figures for a particular council based on the local rag JP covering that council. And the glue is this, added to the process_message() function definition:
def getCodeForTitle(title):
code=jj_titles[jj_titles['name']==title]['code_admin_district'].iloc[0]
return code
if text.startswith("JSA JP"):
jj_titles=pd.read_csv("titles.csv")
title=text.split('JSA JP')[1].strip()
code=getCodeForTitle(title)
outputs.append([data['channel'], nt.otw_rep1(code)])
outputs.append([data['channel'], nt.rateGetter(code)])

This is quite an attractive route, I think, for national newsgroups: anyone in the group can create a bot to generate press release style copy at a local level from a national dataset, and then make it available to reporters from other titles in the group – who can simply key in by news title.
But it could work equally well for a community network of hyperlocals, or councils – organisations that are locally based and individually do the same work over and over again on national datasets.
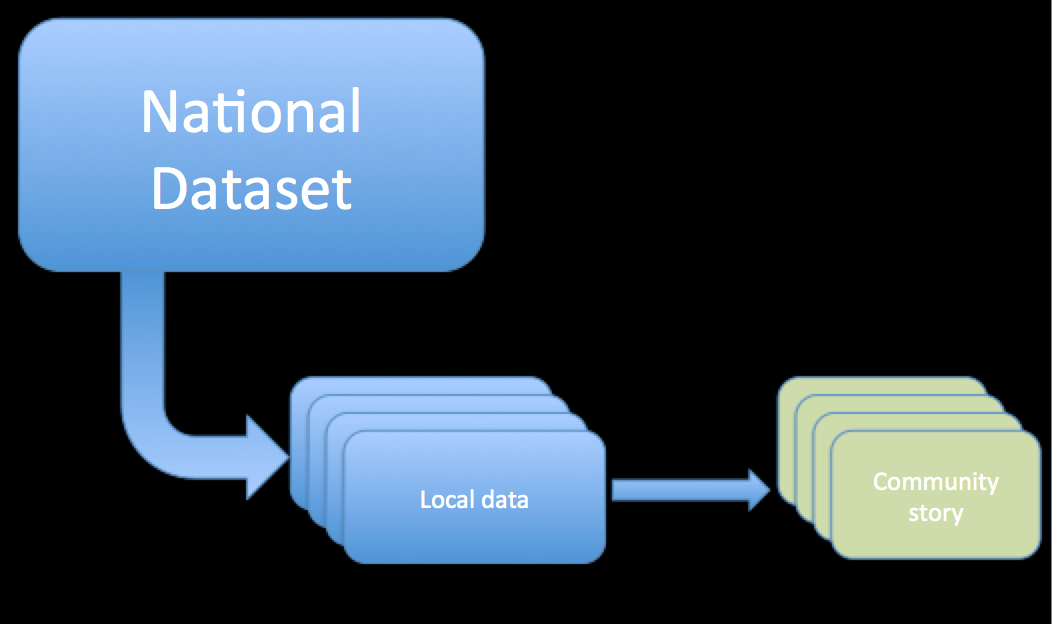
The general flow is something a bit like this:
which has a couple of very obvious pain points:
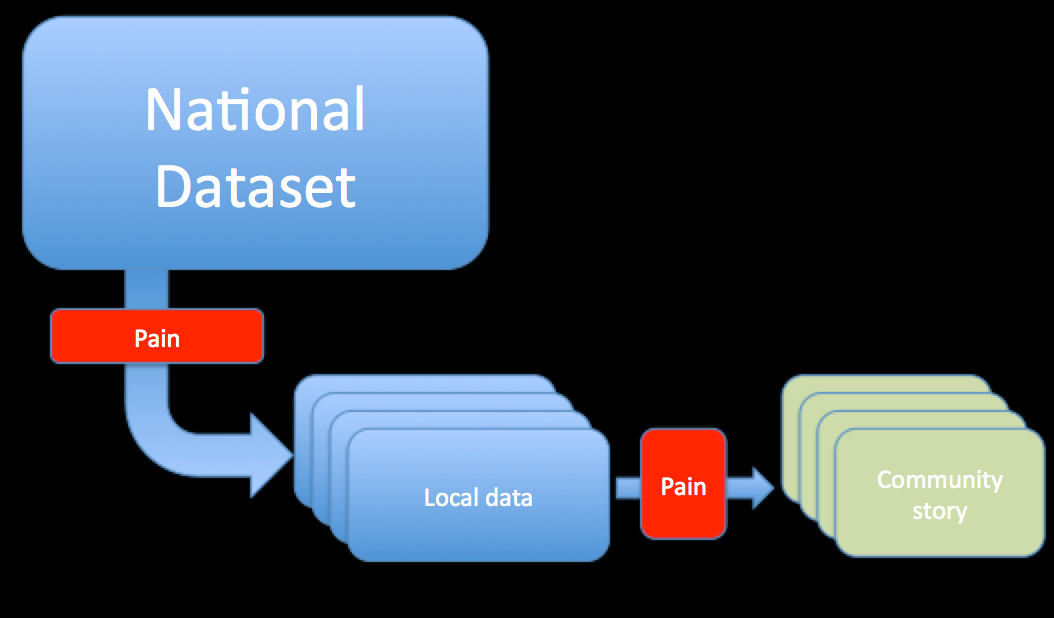
Firstly, finding the local data from the national data, cleaning the data, etc etc. Secondly, making some sort of sense of the data, and then doing some proper journalistic work writing a story on the interesting bits, putting them into context and explaining them, rather than just relaying the figures.
What the automation route does is to remove some of the pain, and allow the journalist to work up the story from the facts, presented informatively.
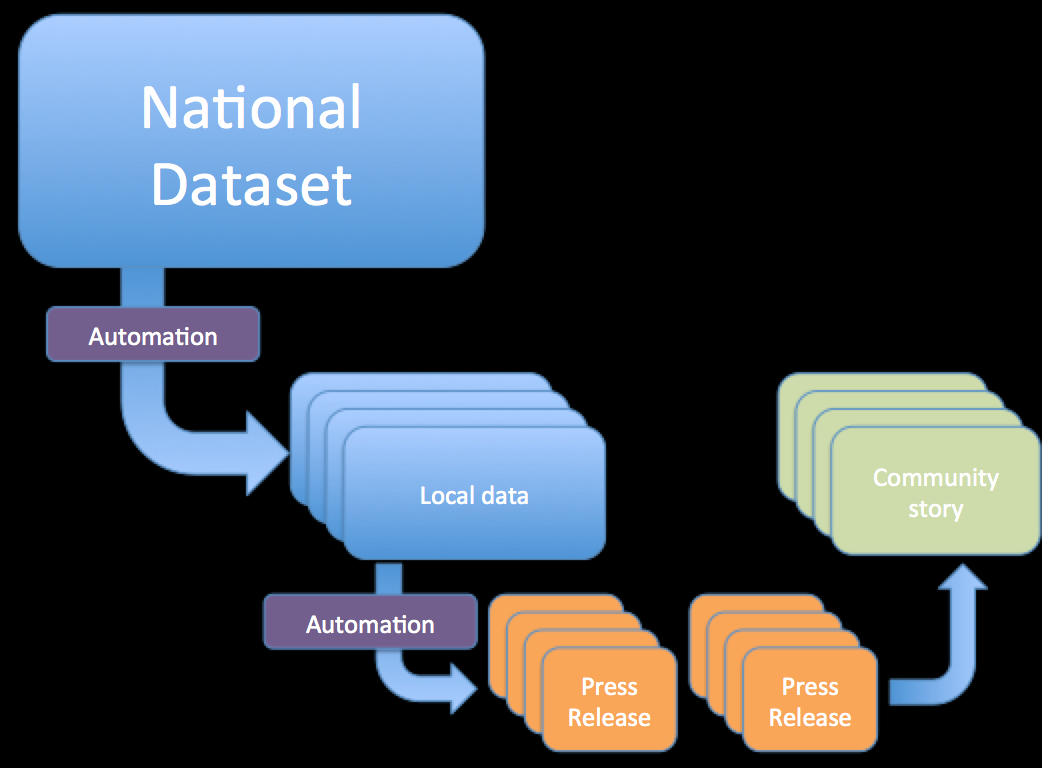
This is a model I’m currently trying to work up with OnTheWight and one I’ll be talking about briefly at the What next for community journalism? event in Cardiff on Wednesday [slides].
PS Hmm.. this just in, The Future of the BBC 2015 [PDF] [announcement].
Local Accountability Reporting Service
Under this proposal, the BBC would allocate licence fee funding to invest in a service that reports on councils, courts and public services in towns and cities across the UK. The aim is to put in place a network of 100 public service reporters across the country.
Reporting would be available to the BBC but also, critically, to all reputable news organisations. In addition, while it would have to be impartial and would be run by the BBC, any news organisation — news agency, independent news provider, local paper as well as the BBC itself—could compete to win the contract to provide the reporting team for each area.
A shared data journalism centre Recent years have seen an explosion in data journalism. New stories are being found daily in government data, corporate data, data obtained under the Freedom of Information Act and increasing volumes of aggregated personalised data. This data offers new means of sourcing stories and of holding public services, politicians and powerful organisations to account.
We propose to create a new hub for data journalism, which serves both the BBC and makes available data analysis for news organisations across the UK. It will look to partner a university in the UK, as the BBC seeks to build a world-class data journalism facility that informs local, national and global news coverage.
A News Bank to syndicate content
The BBC will make available its regional video and local audio pieces for immediate use on the internet services of local and regional news organisations across the UK.
Video can be time-consuming and resource-intensive to produce. The News Bank would make available all pieces of BBC video content produced by the BBC’s regional and local news teams to other media providers. Subject to rights and further discussion with the industry we would also look to share longer versions of content not broadcast, such as sports interviews and press conferences.
Content would be easily searchable by other news organisations, making relevant material available to be downloaded or delivered by the outlets themselves, or for them to simply embed within their own websites. Sharing of content would ensure licence fee payers get maximum value from their investment in local journalism, but it would also provide additional content to allow news organisations to strengthen their offer to audiences without additional costs. We would also continue to enhance linking out from BBC Online, building on the work of Local Live.
Hmm… Share content – or share “pre-content”. Use BBC expertise to open up the data to more palatable forms, forms that the BBC’s own journalists can work with, but also share those intermediate forms with the regionals, locals and hyperlocals?