A new course is in planning on machine learning, intended to be a required part of a data science qualification, driven by the Maths department. Interestingly, our data management and analysis course will not be a required course on that qualification (practical issues associated with working with data are presumably not relevant).
I also suspect that several approaches we could take to teaching machine learning related topics will be ruled as out of scope because: maths and equations…
There are ways I think we can handle talking about equations. For example, Diagrams as Graphs, and an Aside on Reading Equations.
One of the distinguishing features of many OU courses is their strong narrative. In part this reflects the way in which material is presented to students: as the written word (occasionally embellished with video and audio explanations). OU materials also draw heavily on custom produced media assets: diagrams and animations, for example. We used to be a major producer of educational software applications, but as the development of web browsers has supported more interactivity, I get the feeling our courses have gone the other way. This is perhaps because of the overheads associated with developing software applications and then having to maintain them, cross-platform, for five years or more of a course’s life.
I also think OU material design, and the uniqueness of our approach, is under threat from things like notebook style interfaces being adopted and used by other providers. But that’s a subject for another post…
So in a new course on machine learning, in a world where there has been a recent flurry of text book publications (often around particular programming libraries that help you do machine learning) and an ever increasing supply of repositories on Github containing notebook based tutorials and course notes, what narrative twist should we apply to the story of machine learning to support the teaching of its underlying principles?
I typically favour a technology approach, where we use the technology to explore the technology, try to situate it in a practical context where we consider social, political, legal and ethical issues of using the technology within society, and try to make it relevant by exploring use cases and workflows. The academic component justifies the practical claims with robust mathematical models that provide explanations of how the stuff actually works and what it is actually doing. I also like historical timelines which show the evolution of ideas: sometimes ideas carry baggage with them from decisions that were made early on in the idea’s evolution that maybe wouldn’t be taken the same way today. (Sound familiar?) With a nod to advice given to PhD students going into the viva to defend their thesis, each course (thesis) should implicitly be able to answer the plaintive cry of the struggling student (or thesis examiner): “why should I care?”
So: machine learning. What story do we want to tell?
Having fallen asleep before going to bed last night, then groggily waking up from a rather intense dream in the early hours, this question had popped into my head by the time I made it into bed, took root, and got me back out of bed, wide awake, to scribble some notes. The rest of this post is based on those notes and is not necessarily very coherent…
Lines, planes and spaces
Take a look at the following chart, taken from the House of Commons Library post Budget 2018: The background in 9 charts:

It shows a couple of lines detailing the historical evolution of recorded figures for borrowing/deficit, as well predictions of where the line will go.
Prediction is one of the things we use machine learning for. But what does the machine learning do?
In the above case, we can look at the chart, say each line looks roughly like a straight line, and then create a model in the form of a simple (linear) equation to describe each line:
y = mx + c
We can then plug a year (as the independent x value) in and then get the dependent y value out from it as the modelled borrowing or surplus figure.
The following chart from the UK Met Office of climate temperatures for Southern England over several years shows periodicity, or seasonality of temperatures over months of the year.

If we were to plot temperature over several years, we’d have something like a sine wave, which again we can model as a simple equation:
y = a * sin( (b * x) + c).
Lines with more complex periodicities can be modelled by more complex equations as described by the composition of several sine waves, identified using Fourier analysis (Fourier, Laplace and z-transforms are just magical…).
But we don’t need to use machine learning to identify the equations of those lines, we can simply analyse them using techniques developed hundreds of years ago, made ever more accessible via a single line of code (example).
Some equations that define a line actually feed on themselves. If you think back to primary school days maths lessons, you may remember being set questions of the form: what is the next number in this series?
In this case, the equation iterates. For example, the famous Fibonacci sequence — 0, 1, 1, 2, 3, 5, 8, … — is defined as:

The equation eats itself.
Although we don’t need machine learning to help us match these equations to a particular data set, machines can help us fit them. For example, if we have guessed the right form of equation to fit a set of data points (for example, y = mx + c) a machine can quickly help identify the values of m and c, or perform a Fourier analysis for us.
If we aren’t sure what equation might fit a set of data, we could use a machine to try out lots of different sorts of equation against a dataset, calculate the error on each (that is, how well it predicts data values when it is “best fit”) and then pick the one with the lowest error as the best fit equation. We could argue this as a weak form of a learning about what equation type from a preselected set best fits the data.
The aim, remember, is to come up with the equation of a line, or, where we have more than two dimensions, a plane or surface) so that we can predict a dependent variable from one or more independent variables.
That may sound confusing, but you already have a folk mathematical sense of how this works: X is male, morbidly obese and 5 feet 6 inches tall. About how much does he weigh?
To estimate X’s weight, you might treat it as a prediction exercise and model that question in the form of an equation that predicts a ‘normal’ weight for that gender and height (two independent variables) then scales it in some way according to the label morbidly obese. If you’re a medic, you may define the morbidly obese term formally. If you aren’t, you may treat it as an arbitrary label that you associate, perhaps in a personally biased way, with a particular extent of overweightness.
There is another way you might approach the same question, and that is as something more akin to a classification task. For example, you know lots of people; you know, ish, their weights; you imagine which group of people X is most like and then estimate his weight based on the weight of people you know in that group.
Equations still have a role to play here. If you imagine the world of people as “tall and slight”, “tall and large”, “short and slight”, “short and large” and “average”, you may imagine the classification space as being constructed something like this:
 Distinctions defined over each of the axes and then combined to make the final classification. You might then associate further (arbitrary) labels with the different classifications: “short and slight” might be relabelled “small” for example. Other categories might be relabelled “large”, “wide” and “lanky” (can you work out which they would apply to?). This relabelling is subjective and for our “benefit”, not the machine’s, to make the categories memorable. Memorable to our biases, stereotypes and preconceptions. It can also influence our thinking when we could to refer to the groups by these labels at a later stage…
Distinctions defined over each of the axes and then combined to make the final classification. You might then associate further (arbitrary) labels with the different classifications: “short and slight” might be relabelled “small” for example. Other categories might be relabelled “large”, “wide” and “lanky” (can you work out which they would apply to?). This relabelling is subjective and for our “benefit”, not the machine’s, to make the categories memorable. Memorable to our biases, stereotypes and preconceptions. It can also influence our thinking when we could to refer to the groups by these labels at a later stage…
So here then is another thing that we might look to machine learning for: given a set of data, can we classify items that are somehow similar along different axes and label them as a separate identifiable groupings. Firstly, for identification purposes (which group does this item belong to). Secondly, in combination with predictive models defined within those groupings, to allow us to make predictions about things we have classified in one way, and perhaps different predictions about things classified another way.
Again, we need to come up with equations that allow us to make distinctions (above the line or below the line, to the left of the line or to the right, within the box or outside the box) so we can run the data against those equations and make a categorisation.
Again, we don’t necessarily need “machine learning” to help us identify these equations, if we assume a particular classification model. For example, the k-means technique allows you to say you want to find k different groupings within a set of data and it will do that for you. For k=5, it will fit a set of equations that will group the data into five categories. But again, we might want to throw a set of possible models at the data and then pick the one that best works, which a machine can automate for us. A weak sort of learning, at best.
So what is machine learning?
It’s what you do when you don’t know what model to use. It’s what you do when you throw a set of data at a computer and say: I have no idea. You make sense of it. You find what equations to use and how to combine them. And it doesn’t matter if can’t understand or make sense of any of them. As far as I’m concerned, I’m model free and theory free. Go at it.
Of course, the machine may learn rules that are understandable, and that weren’t what you expected:

When feeding a machine, you need to be wary of what you feed it.
In telling the story of machine learning, then, do we need to do any of that ‘precursor’ stuff, of lines and planes and what we can do just anyway using ‘traditional’ mathematical techniques, perhaps with added automation so we can try lots of pre-defined models we can fit quickly? Or should we just get straight on to the machine learning bits? There is only so much time, breadth and depth available to us when delivering the course, after all.
I think we do…
Throughout the course, those foundational ideas would provide a ground truth that a student can use to anchor themselves back to the questions of: what am I (which is to say, the machine) actually trying to do? and why are we using machine learning? Don’t we have a theory about the data use a model based on that?
So what about spaces. What are they, and do we need to know about them?
When I put together the OU short course on game design and development (I knew nothing about that, either) I came across the idea of lenses, different ways of looking at a problem that bring different aspects of it into focus. Here’s a set of six lenses commonly used in news reporting: who?, what?, why?, when?, where?, how?.
When we pull together a dataset around which we want to make a set of predictions, or classifications, or classification based predictions, we define a space of inquiry within which we want to ask particular questions. In the classification example above, the space I came up with was a lazy one: something distinguishing and recognisable about people that I can identify different groupings within. Within that space I then identified a set of metrics (measurable things) that I could determine within it (height and weight). Already things are a bit arbitrary and subject to bias. Who chose the space? Why? What do they want to make those classifications for? Who chose the metrics? What population provided the data? How was the data collected? When was it collected? Where? Could any of that make a difference? (Like only using a particular machine for suspected hip fractures, and marking records urgent if there is a hip fracture evident in an x-ray, for example…) Is there, perhaps, a theory or an intuitive model we can apply to a dataset to perform a particular task that doesn’t mean we need to take the last resort of machine learning (“if machine X and marked urgent, then hip fracture”).
We might also create a space out of nowhere around the data we have. A space we can go fishing in but that we don’t really understand.
So another bedrock I think we need in a course on machine learning, another storyline we can call on, is a set of questions, a set of lenses, that we can use to identify what space our data lies in, as well as critically interrogating the metrics we impose upon it and from which we (via our machines) develop our machine learned models.
Readers who know anything about machine learning, which I don’t, really, will notice I never even got as far as talking about things like supervised learning, unsupervised learning, reinforcement learning, etc, let alone the different approaches or implementations we might take towards them. That’s the next part of the story we need to think about… This first part was more about getting a foundation stone in place that students can refer back to: “what is this thing actually trying to do?”, rather than “how is it going about it?”
PS By the by, the “lines and spaces” refrain puts me in mind of Wassily Kandinsky’s Point and Line to Plane. As it’s over 30 years ago since I last read it, and I still carry the title with me, I should probably read it again.
















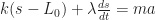


 ) times the amount the spring has stretched (
) times the amount the spring has stretched ( ), which is to say the difference (
), which is to say the difference ( ) between the distance between the wall and the trolley (
) between the distance between the wall and the trolley ( ) and the original length of the spring (
) and the original length of the spring (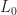 ).
).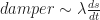
 presumably reads as something like the rate at which the distance between the wall and the trolley changes or the speed with which the trolley moves towards and away from the wall. And
presumably reads as something like the rate at which the distance between the wall and the trolley changes or the speed with which the trolley moves towards and away from the wall. And 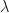 (greek symbol, pronounced as lambda) is another constant material property of the damper.
(greek symbol, pronounced as lambda) is another constant material property of the damper.













