In Fragments – Fuzzy Search, Pattern Matching and Retrieval Using Python and SQLite, I noted the hugely powerful SQLite feature that allows you to create custom application defined SQLite functions that can be used as part of a query. The examples I gave included functions for retrieving a record based on fuzzy matching a particular search term within the record. (Not shown, but also supported, are custom aggregegate functions that can be used as part of a grouping operator.)
The custom functions MUST return a single, not-iterable, scalar value. But what if you want to return multiple items retrieved from within a single record? Which is to say, what if you need to retrun a table from a query onto a record?
Poking around in the SQLite docs, it seems as if you can define functions that return a virtual table as part of an extension. But how might you acheive a similar thing with a simpler Python API?
A quick search turns up a really magical recipe, described by Charles Leifer in SQLite Table-Valued Functions with Python and implemented in the coleifer/sqlite-vtfunc package.
All you need to do is define a class with a couple of methods: an initialisation routine that creates an iterator over the items you want to return via the virtual table; and an iterator that returns each row for your return table. Provide the names of you input arguments and output columns, and that’s pretty much it.
So here’s an example, based on an old code fragment I came across for highlighting typos whilst looking for something else (which reminds me: I still haven’t found the post I was looking for…).
The code uses the jxmorris12/language_tool_python package that provides a Python API to the Java’n’http server based LanguageTool spellchecking server and returns highlighted typographical errors in the presented text.
So can we riff on that to create a spell-checker that we can apply to records in a SQLite database, and for each record return rows of a “spellcheck” virtual table with one typo per row?
Let’s start with a class that creates the spellchecker. When you call the languagetool, it takes forever to start up an server, so it makes sense to create a class wrapper with a global language server, assuming that you’re working in a single language.
# %pip install --upgrade language_tool_python
import language_tool_python
# Loading the languagetool is slow, so it makes sense to only do it once.
# So put it in a class and refer to it from a persistent object context
class TypoHighlighter:
"""Find typographical errors in a text and highlight them.
Note that this class make be slow to instantiate as the
LanguageTool http server started.
"""
# Shared instance
tool = language_tool_python.LanguageTool('en-UK')
def __init__(self, style='html', #lang='en-UK',
html_color='red', md_style='__'):
self.style = style
#self.lang = lang
self.html_color = html_color
self.md_style = md_style
def typo_styler(self, error):
"""Highlight error term."""
typo = error.context
from_ = error.offsetInContext
to_ = from_ + error.errorLength
txt = typo[from_:to_]
if self.style=='html':
typo = typo[:from_] + f'<span style="color:{self.html_color}">{txt}</span>{typo[to_:]}'
elif not None:
typo = f"{typo[:from_]}{self.md_style}{txt}{self.md_style}{typo[to_:]}"
#print(f"**{html}")
return typo
def highlight_typos(self, text, highlight=True):
"""Highlight spelling errors in text."""
matches = TypoHighlighter.tool.check(text)
if not highlight:
return matches
else:
return [self.typo_styler(m) for m in matches]
We can then run the spellchecker as follows to retrieve the raw response of the spell-checker:
tool = TypoHighlighter()
text = 'This sentence is fine. A sentence with a error in the Hitchhiker’s Guide tot he Galaxy'
matches = tool.highlight_typos(text, False)
matches
"""
[Match({'ruleId': 'EN_A_VS_AN', 'message': 'Use “an” instead of ‘a’ if the following word starts with a vowel sound, e.g. ‘an article’, ‘an hour’.', 'replacements': ['an'], 'offsetInContext': 39, 'context': 'This sentence is fine. A sentence with a error in the Hitchhiker’s Guide tot he ...', 'offset': 39, 'errorLength': 1, 'category': 'MISC', 'ruleIssueType': 'misspelling', 'sentence': "A sentence with a error in the Hitchhiker's Guide tot he Galaxy"}),
Match({'ruleId': 'TOT_HE', 'message': 'Did you mean “to the”?', 'replacements': ['to the'], 'offsetInContext': 43, 'context': '... with a error in the Hitchhiker’s Guide tot he Galaxy', 'offset': 73, 'errorLength': 6, 'category': 'TYPOS', 'ruleIssueType': 'misspelling', 'sentence': "A sentence with a error in the Hitchhiker's Guide tot he Galaxy"})]
"""
Or we can get inline highlighted errors:
matches = tool.highlight_typos(text)
matches
"""
['This sentence is fine. A sentence with <span style="color:red">a</span> error in the Hitchhiker’s Guide tot he ...',
'... with a error in the Hitchhiker’s Guide <span style="color:red">tot he</span> Galaxy']
"""
So how might we make use of this in a SQLite context?
Let’s start with the error highlighter, where we just return a simple string that shows each error, in context, with the error highlighted. If we run our function over a record in the database, we want to return a set of rows with a single column that contains that highlighted text.
We start the declaration of the class as follows, defining the input argument(s), the column names for the virtual table output, the name of the custom function we can call in a SQLite SQL query, and a class global spellchecker object to perform the spell check:
class DBTypoHighlighter(TableFunction):
# Input parameter - the text we want to check for typos
params = ['text']
# A single output column containing highlighted errors in context
columns = ['highlight']
# The name of the function we can call in SQLite
name = 'typo_highlighter'
# A class global spellchecker object
typo_highlighter = TypoHighlighter()
The next thing we need to do is define an initialisation function inside the class that will return an iterator over items we are to return on a per row basis inside our virtual table. The spellchecker returns a Python list containing separate error items, which we can easily return as an iterator:
def initialize(self, text=None):
"""Return an iterator to generate output virtual table rows."""
self._iter = iter(DBTypoHighlighter.typo_highlighter.highlight_typos(text))
Next, we need to define the iterator method for the class that returns each row:
def iterate(self, idx):
"""Return the next row for the virtual table."""
# We don't need to make us of the idx value
# but it is required in the methof signature
item = next(self._iter)
# The final , is required.
return (item,)
We can now register the function with a SQlite database object:
from sqlite_utils import Database
db = Database('test.db')
DBTypoHighlighter.register(db.conn)
We should now be able to run a typo_highlighter() query over a test string:
text = 'This sentence is fine. A sentence with a error in the Hitchhiker’s Guide tot he Galaxy'
for i in db.execute(f'SELECT * FROM typo_highlighter("{text}");'):
print(i)
"""
('This sentence is fine. A sentence with <span style="color:red">a</span> error in the Hitchhiker’s Guide tot he ...',)
('... with a error in the Hitchhiker’s Guide <span style="color:red">tot he</span> Galaxy',)
"""
And if we can run it over one string, we can apply it to multiple rows in a query:
spelltests = db["spelltests"]
# Add some rows
spelltests.insert({'id':1,
'text':'This sentence is fine. A sentence with a error in the Hitchhiker’s Guide tot he Galaxy'})
spelltests.insert({'id':2,
'text':'A sentence with a error in the Hitchhiker’s Guide tot he Galaxy'})
spelltests.insert({'id':3,
'text':'This sentence is fine.'})
# Run our spellchecker over the rows
for i in db.execute(f'SELECT * FROM spelltests, typo_highlighter(spelltests.text);'):
print(i)
"""
(1, 'This sentence is fine. A sentence with a error in the Hitchhiker’s Guide tot he Galaxy', 'This sentence is fine. A sentence with <span style="color:red">a</span> error in the Hitchhiker’s Guide tot he ...')
(1, 'This sentence is fine. A sentence with a error in the Hitchhiker’s Guide tot he Galaxy', '... with a error in the Hitchhiker’s Guide <span style="color:red">tot he</span> Galaxy')
(2, 'A sentence with a error in the Hitchhiker’s Guide tot he Galaxy', 'A sentence with <span style="color:red">a</span> error in the Hitchhiker’s Guide tot he ...')
(2, 'A sentence with a error in the Hitchhiker’s Guide tot he Galaxy', '... with a error in the Hitchhiker’s Guide <span style="color:red">tot he</span> Galaxy')
"""
So that seems to works:-)
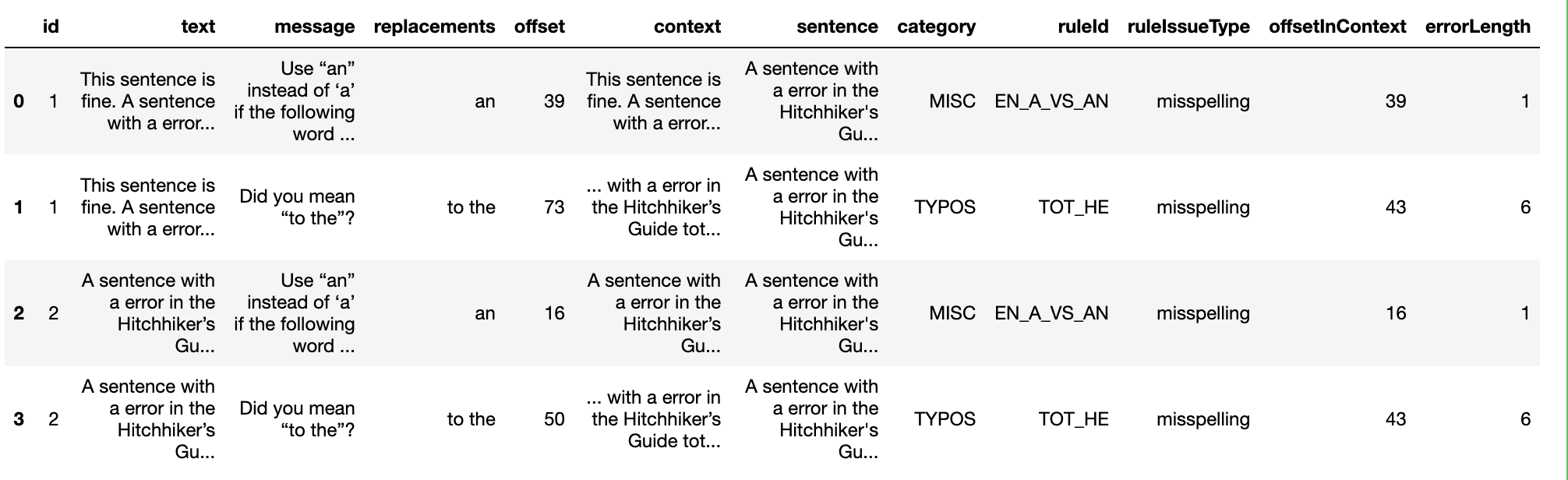
How about a more general function that returns more complete tabling detailing the errors as found by the languagetool, with the virtual table containing separate columns for each element in the language tool error object.
We note that one of the attributes (replacements) is returned as a list, which we need to serialise somehow, either by returning just the first item, or creating a single string from all the listed suggestions, with each item distinguished wihtn that string.
Constructing the class proceeds as before, although this time we need to make sure we declare all the columns we want to return in the virtual table, and make sure that the iterator method populates those columns appropriately:
class DBTypoFinder(TableFunction):
"""Return a virtual table containing error data associated
with typos in the presented text."""
params = ['text']
columns = ['message', 'replacements', 'offset', 'context',
'sentence', 'category', 'ruleId', 'ruleIssueType',
'offsetInContext', 'errorLength']
name = 'typo_finder'
typo_highlighter = TypoHighlighter()
def initialize(self, text=None):
self._iter = iter(DBTypoHighlighter.typo_highlighter.highlight_typos(text, False))
def iterate(self, idx):
i = next(self._iter)
return (i.message, '::'.join(i.replacements), i.offset, i.context,
i.sentence, i.category, i.ruleId, i.ruleIssueType,
i.offsetInContext, i.errorLength,)
DBTypoFinder.register(db.conn)
When we run this query, we get back a much richer table:
import pandas as pd
pd.read_sql('SELECT * FROM spelltests, typo_finder(spelltests.text);',
db.conn)
This recipe is so much fun! :-)
