[An old post, rescued from the list of previously unpublished posts…]
Although I use OpenRefine from time time, one thing I don’t tend to use it for is screenscraping HTML web pages – I tend to write Python scripts in Scraperwiki to do this. Writing code is not for everyone, however, so I’ve brushed off my searches of the OpenRefine help pages to come up with this recipe for hacking around with various flavours of company data.
The setting actually comes from OpenOil’s Johnny West:
1) given the companies in a particular spreadsheet… for example “Bayerngas Norge AS” (row 6)
2) plug them into the Norwegian govt’s company registry — http://www.brreg.no/ (second search box down nav bar on the left) – this gives us corporate identifier… so for example… 989490168
3) plug that into purehelp.no — so http://www.purehelp.no/company/details/bayerngasnorgeas/989490168
4) the Aksjonærer at the bottom (the shareholders that hold that company) – their percentages
5) searching OpenCorporates.com with those names to get their corporate identifiers and home jurisdictions
6) mapping that back to the spreadsheet in some way… so for each of the companies with their EITI entry we get their parent companies and home jurisdictions
Let’s see how far we can get…
To start with, I had a look at the two corporate search sites Johnny mentioned. Hacking around with the URLs, there seemed to be a couple of possible simplifications:
– looking up company ID can be constructed around http://w2.brreg.no/enhet/sok/treffliste.jsp?navn=Bayerngas+Norge+AS – the link structure has changed since I originally wrote this post, correct form is now http://w2.brreg.no/enhet/sok/treffliste.jsp?navn=Bayerngas+Norge+AS&orgform=0&fylke=0&kommune=0&barebedr=false [h/t/ Larssen in the comments.]
– http://www.purehelp.no/company/details/989490168 (without company name in URL) appears to work ok, so can get there from company number.
Loading the original spreadsheet data into OpenRefine gives us a spreadsheet that looks like this:
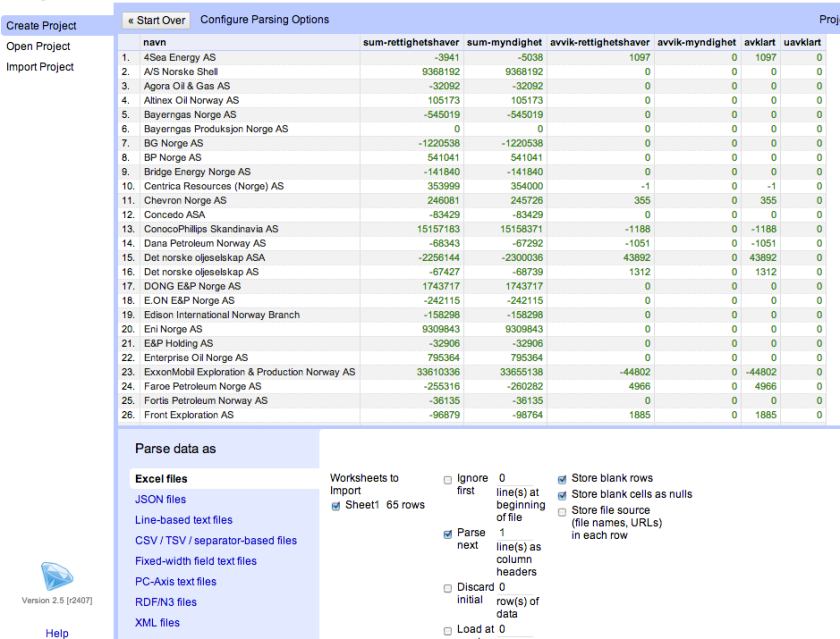
So that’s step 1…
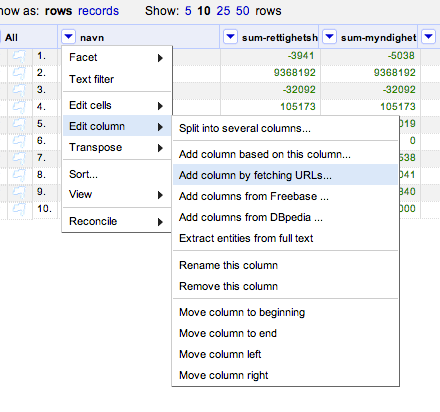
We can run step 2 as follows* – create a new column from the company column:
* see the end of the post for an alternative way of obtaining company identifiers using the OpenCorporates reconciliation API…
Here’s how we construct the URL:
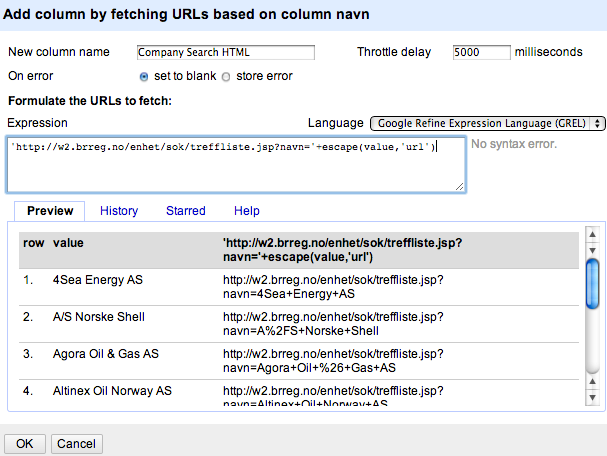
The HTML is a bit of a mess, but by Viewing Source on an example page, we can find a crib that leads us close to the data we require, specifically the fragment detalj.jsp?orgnr= in the URL of the first of the href attributes of the result links.
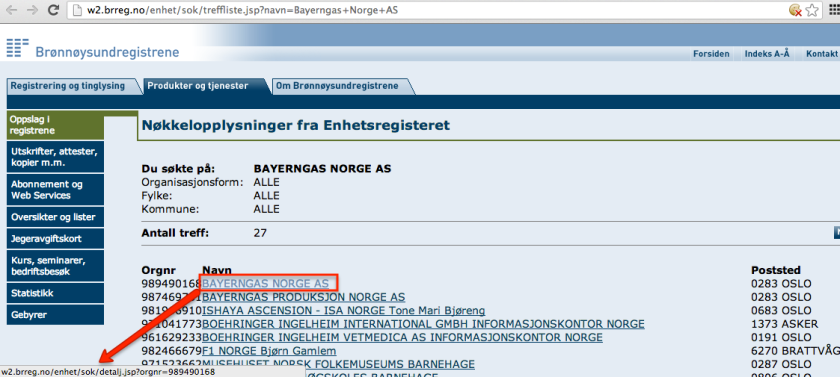
Using that crib, we can pull out the company ID and the company name for the first result, constructing a name/id pair as follows:
[value.parseHtml().select("a[href^=detalj.jsp?orgnr=]")[0].htmlAttr("href").replace('detalj.jsp?orgnr=','').toString() , value.parseHtml().select("a[href^=detalj.jsp?orgnr=]")[0].htmlText() ].join('::')
The first part – value.parseHtml().select("a[href^=detalj.jsp?orgnr=]")[0].htmlAttr("href").replace('detalj.jsp?orgnr=','').toString() – pulls out the company ID from the first search result, extracting it from the URL fragment.
The second part – value.parseHtml().select("a[href^=detalj.jsp?orgnr=]")[0].htmlText() – pulls out the company name from the first search result.
We place these two parts into an array and then join them with two colons: [].join('::')
This keeps thing tidy and allows us to check by eye that sensible company names have been found from the original search strings.
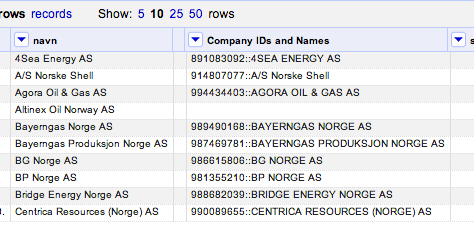
We can now split the name/ID pair column into two separate columns:
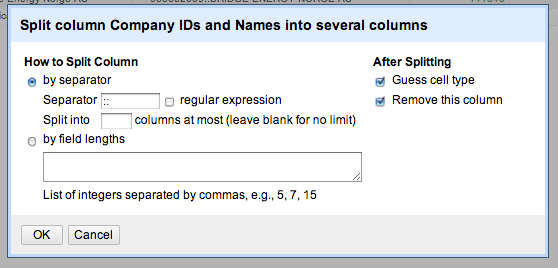
And the result:
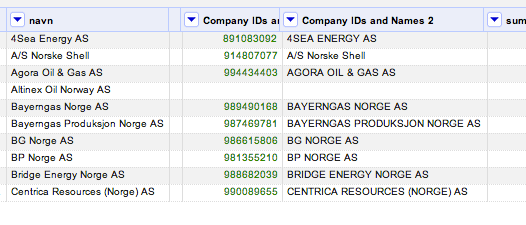
The next step, step 3, requires looking up the company IDs on purehelp. We’ve already see how a new column can be created from a source column by URL, so we just repeat that approach with a new URL pattern:
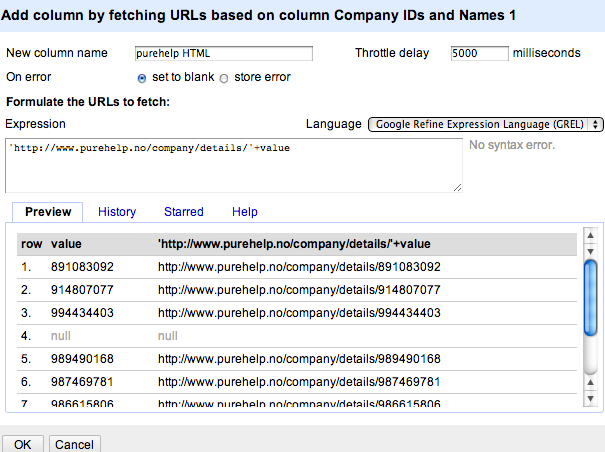
(We could probably reduce the throttle time by an order of magnitude!)
The next step, step 4, is to pull out shareholders and their percentages.
The first step is to grab the shareholder table and each of the rows, which in the original looked like this:
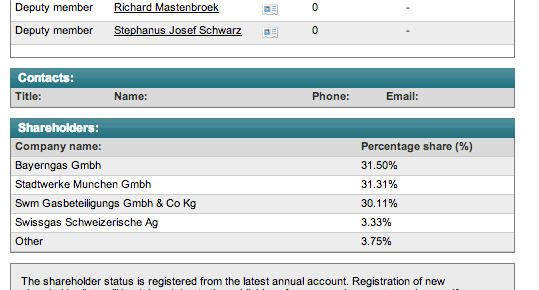
The following hack seems to get us the rows we require:
[REMOVED]
BAH – crappy page sometimes has TWO companyOwnership IDs, when the company has shareholdings in other companies as well as when it has shareholders:-(
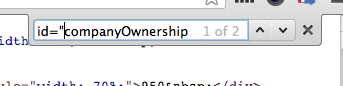
So much for unique IDs… ****** ******* *** ***** (i.e. not happy:-(
Need to search into table where “Shareholders” is specified in top bar of the table, and I don’t know offhand how to do that using the GREL recipe I was taking because the HTML of the page is really horrible. Bah…. #ffs:-(
Question, in GREL, how do I get the rows in this not-a-table? I need to specify the companyOwnership id in the parent div, and check for the Shareholders text() value in the first child, then ideally miss the title row, then get all the shareholder companies (in this case, there’s just one; better example):
<div id="companyOwnership" class="box">
<div class="boxHeader">Shareholders:</div>
<div class="boxContent">
<div class="row rowHeading">
<label class="fl" style="width: 70%;">Company name:</label>
<label class="fl" style="width: 30%;">Percentage share (%)</label>
<div class="cb"></div>
</div>
<div class="row odd">
<label class="fl" style="width: 70%;">Shell Exploration And Production Holdings</label>
<div class="fr" style="width: 30%;">100.00%</div>
<div class="cb"></div>
</div>
</div>
For now I’m going to take a risky shortcut and assume that the Shareholders (are there always shareholders?) are the last companyOwnership ID on the page:
forEach(value.parseHtml().select('div[id=companyOwnership]')[-1].select('div.row'),e,e).join('::')
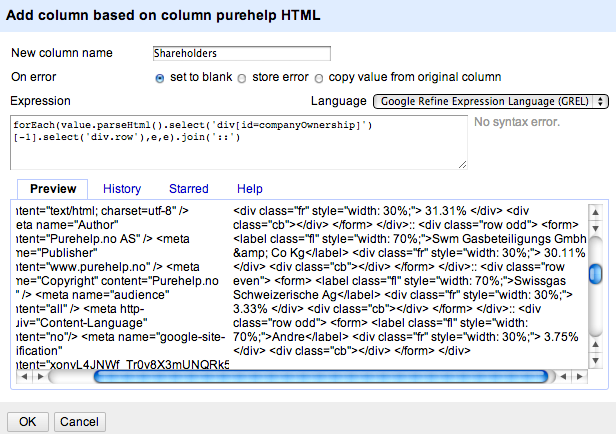
We can then generate one row for each shareholder in OpenRefine:
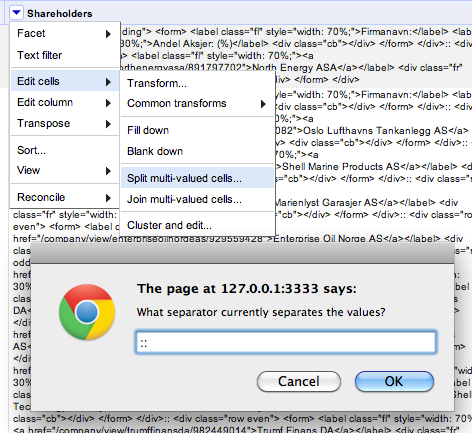
(We’ll need to do some filling in later to cope with the gaps, but no need right now. We also picked up the table header, which has been given it’s own row, which we’ll have to cope with at some point. But again, no need right now.)
For some reason, I couldn’t parse the string for each row (it was late, I was confused!) so I hacked this piecemeal approach to try to take them by surprise…
value.replace(/\s/,' ').replace('<div class="row odd">','').replace('<div class="row even">','').replace('<form>','').replace('<label class="fl" style="width: 70%;">','').replace('<div class="cb"></div>','').replace('</form> </div>','').split('</label>').join('::')
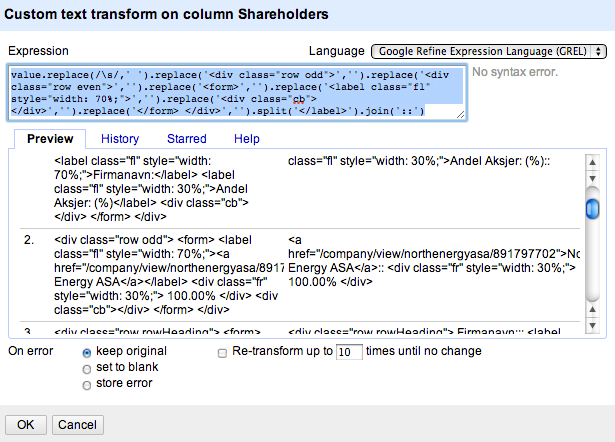
Using the trick we previously applied to the combined name/ID column, we can split these into two separate columns, one for the shareholder and the other for their percentage holding (I used possibly misleading column names below – should say “Shareholder name”, for example, rather than shareholding 1?):

We then need to tidy the two columns:
value.replace("<\/a>",'').replace(/.*>/,'')
Note that some of the shareholder companies have identifiers in the website we scraped the data from, and some don’t. We’re going to be wasteful and throw the info away that links the company if it’s there…
value.replace('<div class="fr" style="width: 30%;">','').replace('</div>','').strip()
We now need to do a bit more tidying – fill down on the empty columns in the shareholder company column and also in the original company name and ID [actually – this is not right, as we can see below for the line Altinex Oil Norway AS…? Maybe we can get away with it though?], and filter out the rows that were generated as headers (text facet then select out blank and Fimanavn).
This is what we get:
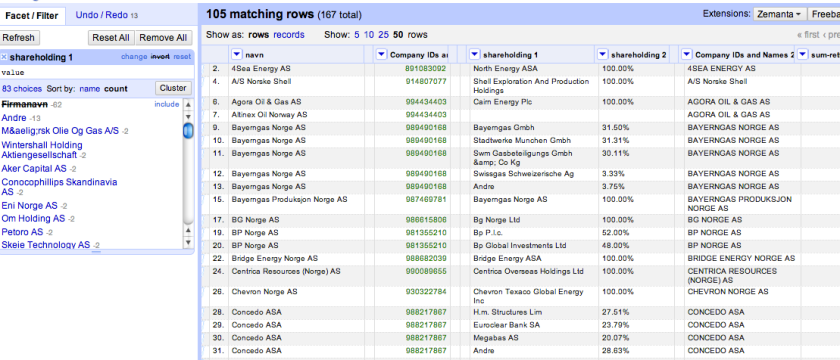
We can then export this file, before considering steps 5 and 6, using the custom exporter:
Select the columns – including the check column of the name of the company we discovered by searching on the names given in the original spreadsheet… these are the names that the shareholders actually refer to…
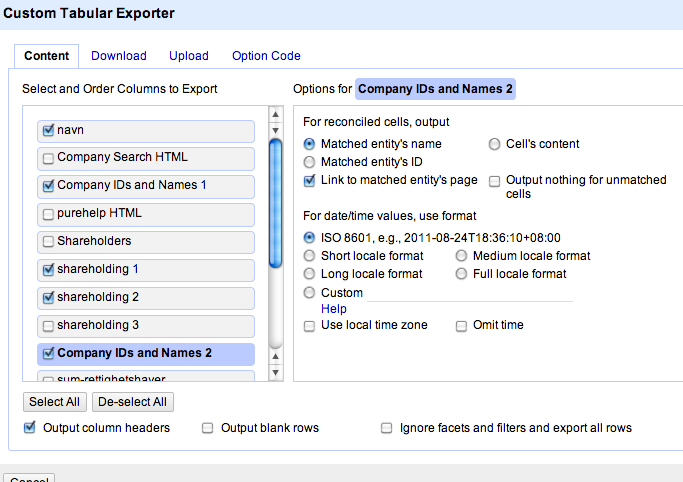
And then select the export format:
Here’s the file: shareholder data (one of the names at least appears not to have worked – Altinex Oil Norway AS). LOoking at the data, I think we also need to take the precaution of using .strip() on the shareholder names.
Here’s the OpenRefine project file to this point [note the broken link pattern for brreg noted at the top of the post and in the comments… The original link will be the one used in the OpenRefine project…]
Maybe export on a filtered version where Shareholding 1 is not empty. Also remove the percentage sign (%) in the shareholding 2 column? ALso note that Andre is “Other”… maybe replace this too?
In order to get the OpenCorporates identifiers, we should be able to just run company names through the OpenCorporates reconciliation service.
Hmmm.. I wonder – do we even have to go that far? From the Norwegian company number, is the OpenCorporates identifier just that number in the Norwegian namespace? So for BAYERNGAS NORGE AS, which has Norwegian company number 989490168, can we look it up directly on OpenCorporates as http://opencorporates.com/companies/no/989490168? It seems like we can…
This means we possibily have an alternative to step 2 – rather than picking up company numbers by searching into and scraping the Norwegian company register, we can reconcile names against the OpenCorporates reconciliation API and then pick up the company numbers from there?





























