In Writing Each Row of a Spreadsheet as a Press Release? I demonstrated how we could generate a simple textual report template that could “textualise” separate rows of a spreadsheet. This template could be applied to each row from a subset of rows to to produce a simple human readable view of the data contained in each of those rows. I picked up on the elements of this post in Robot Journalists or Robot Press Secretaries?, where I reinforced the idea that such an approach was of a similar kind to the approach used in mail merge strategies supported by many office suites.
It also struck me that we could use OpenRefine’s custom template export option to generate a similar sort of report. So in this post I’ll describe a simple recipe for recreating the NHS Complaints review reports from a couple of source spreadsheets using OpenRefine.
This is just a recasting of the approach demonstrated in the Writing Each Row… post, and more fully described in this IPython notebook, so even if you don’t understand Python, it’s probably worth reviewing those just to get a feeling of the steps involved.
To start with, let’s see how we might generate a basic template from the complaints CSV file, loaded in with the setting to parse numerical columns as such.

The default template looks something like this:
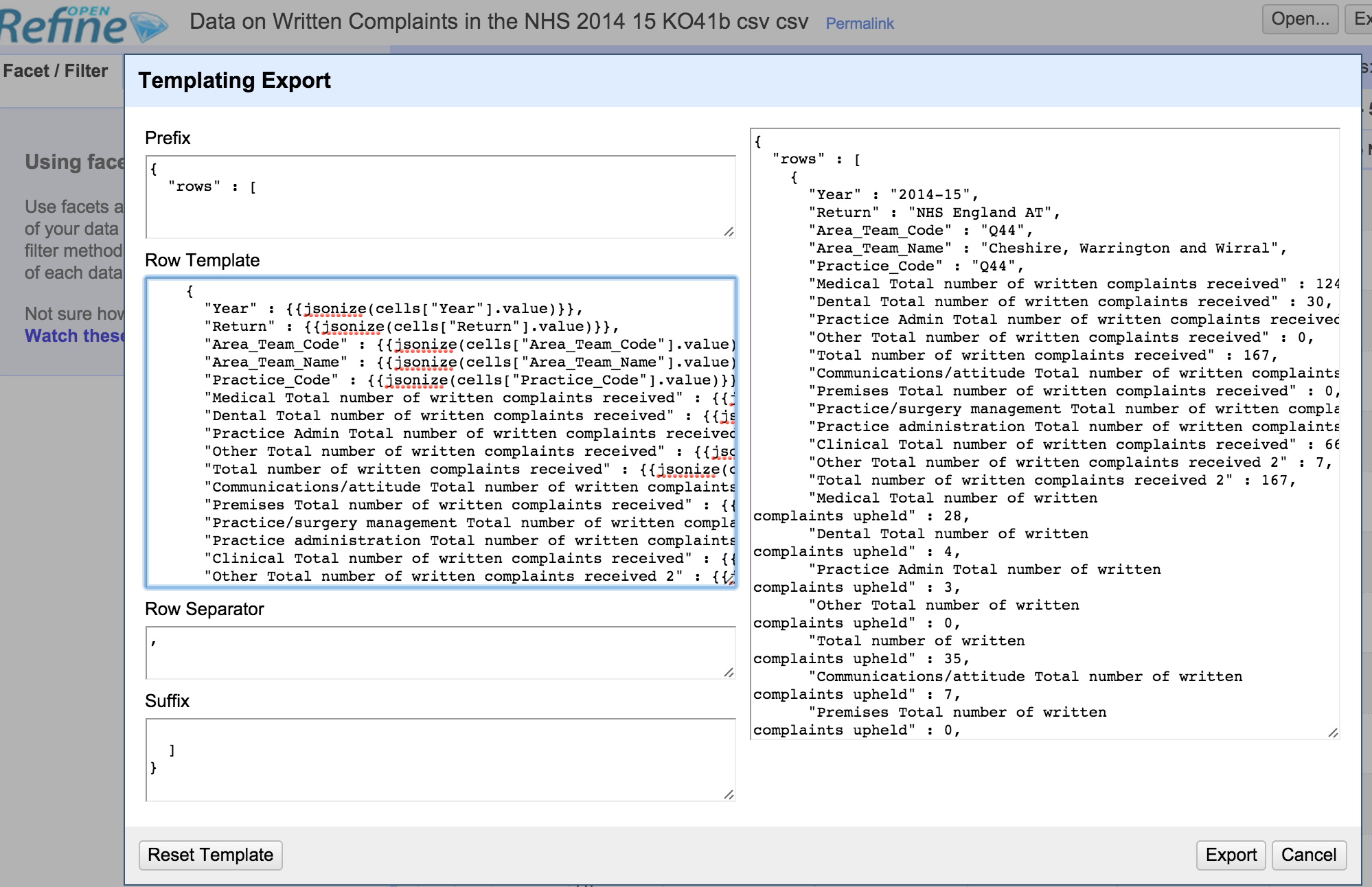
We can see how each the template provides a header slot, for the start of the output, a template applied to each row, a separator to spilt the rows, and a footer.
The jsonize function makes sure the output is suitable for output as a JSON file. We just want to generate text so we can forget that.
Here’s the start of a simple report…
Report for {{cells["Practice_Code"].value}} ({{cells["Year"].value}}):
Total number of written complaints received:
- by area: {{cells["Total number of written complaints received"].value}} (of which, {{cells["Total number of written
complaints upheld"].value}} upheld)
- by subject: {{cells["Total number of written complaints received 2"].value}} (of which, {{cells["Total number of written
complaints upheld 2"].value}} upheld)
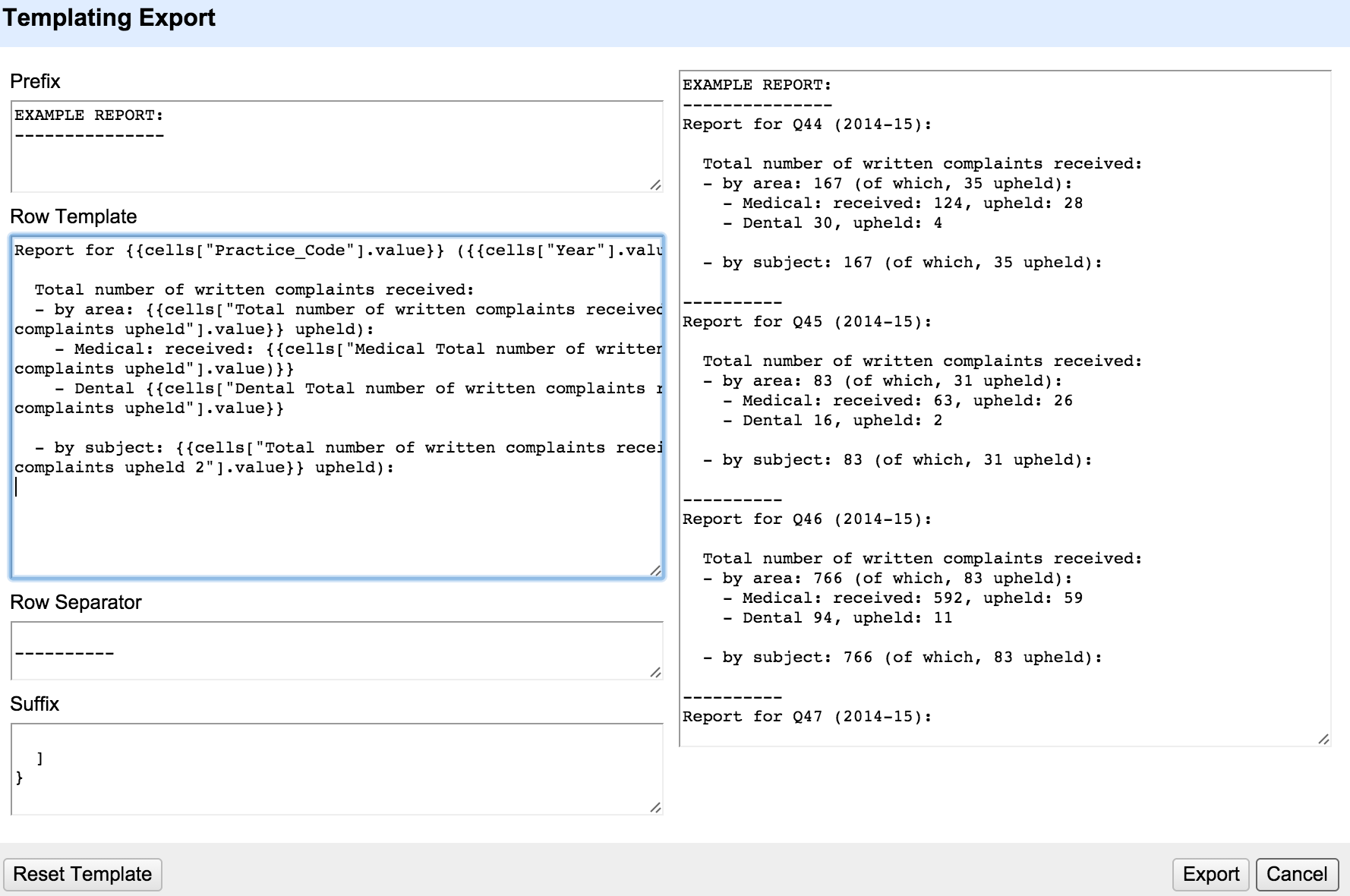
The double braces ({{ }} allow you to access GREL statements. Outside the braces, the content is treated as text.
Note that the custom template doesn’t get saved… I tend to write the custom templates in a text editor, then copy and paste them into OpenRefine.
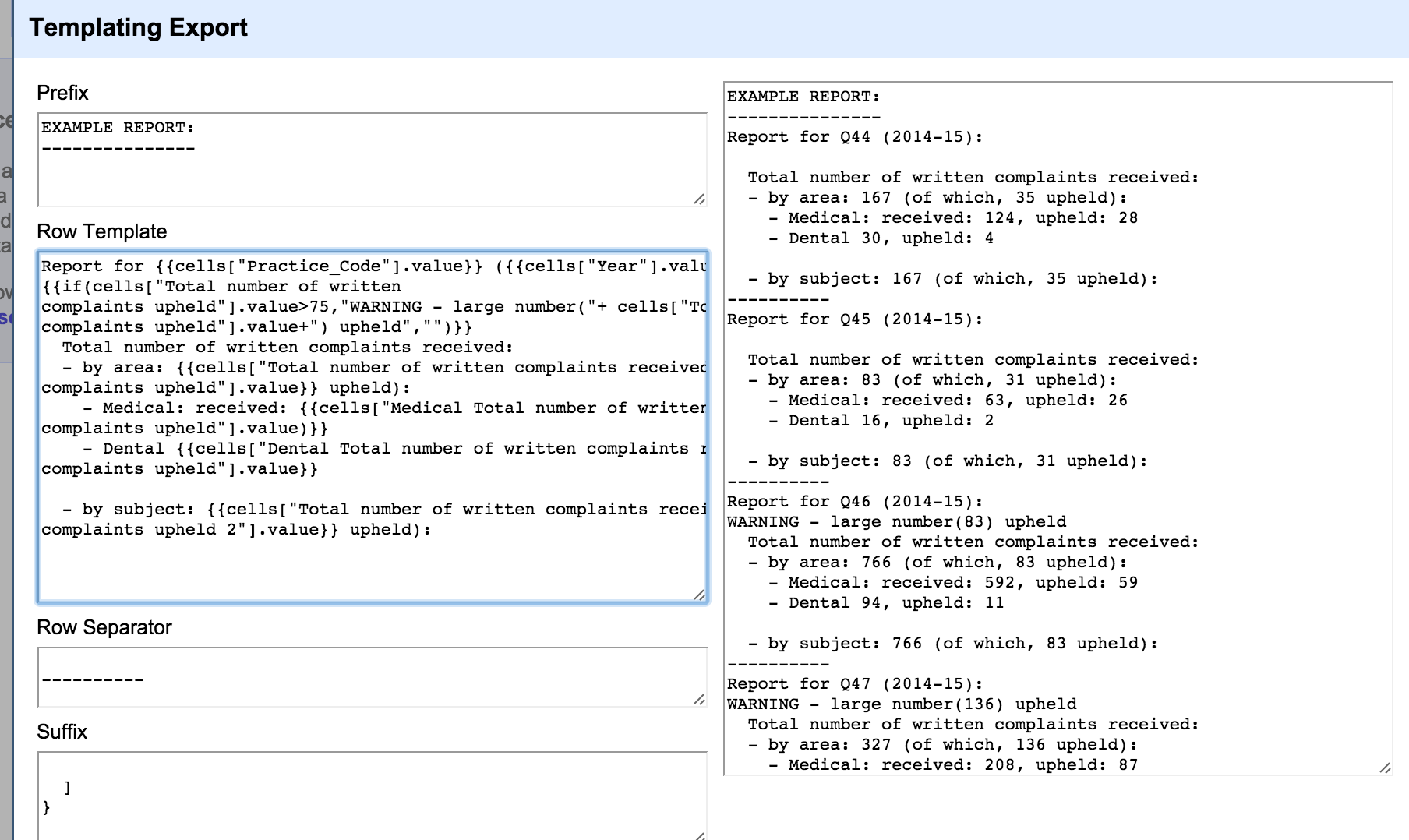
We can also customise the template with some additional logic using the if(CONDITION, TRUE_ACTION, FALSE_ACTION) construction. For example, we might flag a warning that a lot of complaints were upheld:
The original demonstration pulled in additional administrative information (practice name and address, for example) from another source spreadsheet. Merging Datasets with Common Columns in Google Refine describes a recipe for merging in data from another dataset. In this case, if our source is the epraccur spreadsheet, we can create an OpenRefine project from the epraccur spreadsheet (use no lines as the header – it doesn’t have a header row) and then merge in data from the epraccur project into the complaints project using the practice code (Column 1 in the epraccur project) as the key column used to add an additional practice name column based on the Practice_Code column in the complaints project – cell.cross("epraccur xls", "Column 1").cells["Column 2"].value[0]
Note that columns can only be merged in one column at a time.
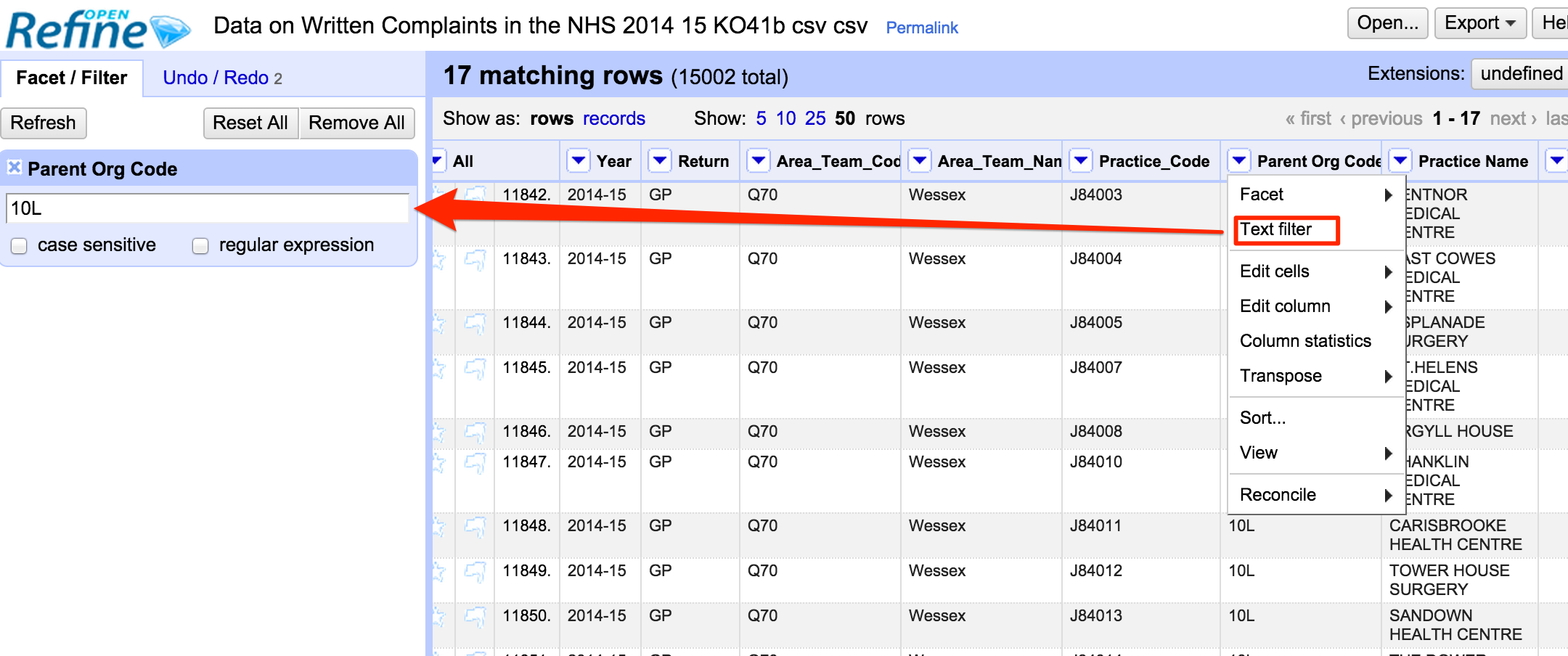
In order to filter the rows so we can generate reports for just the Isle of Wight, we also need to merge in the Parent Organisation Code (Column 15) from the epraccur project. To get Isle of Wight practices, we could then filter on code 10L. If we then used out custom exporter template, we could get just textual reports for the rows corresponding to Isle of Wight GP practices.
Teasing things apart a bit, we also start to get a feel for a more general process. Firstly, we can create a custom export template to generate a textual representation of each row in a dataset. Secondly, we can use OpenRefine’s filtering tools to select which rows we want to generate reports from, and order them appropriately. Thirdly, we could also generate new columns containing “red flags” or news signals associated with particular rows, and produce a weighted sum column on which to rank items in terms of newsworthiness. We might also want to merge in additional data columns from other sources, and add elements from those in to the template. Finally, we might start to refine the export template further to include additional logic and customisation of the news release output.
See also Putting Points on Maps Using GeoJSON Created by Open Refine for a demo of how to generate a geojson file using the OpenRefine custom template exporter as part of a route to getting points onto a map.














