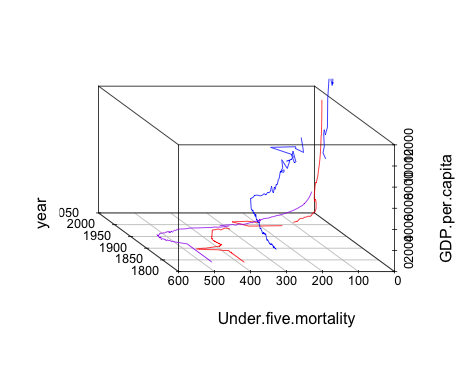
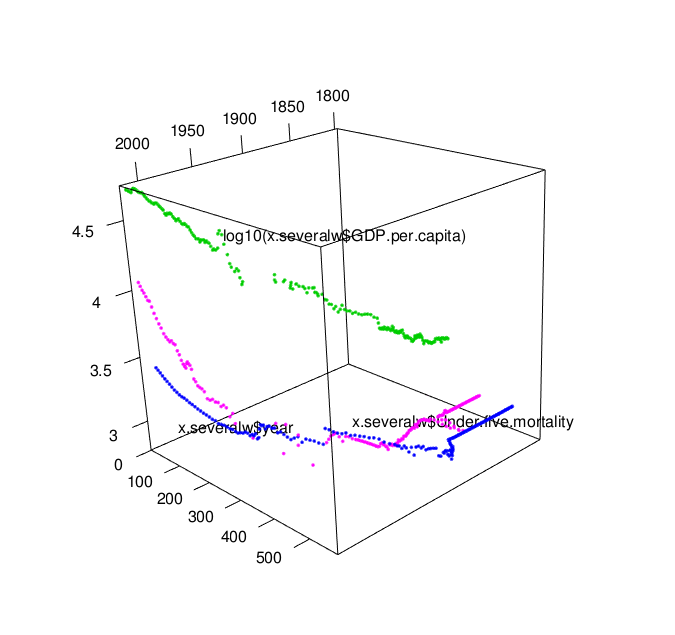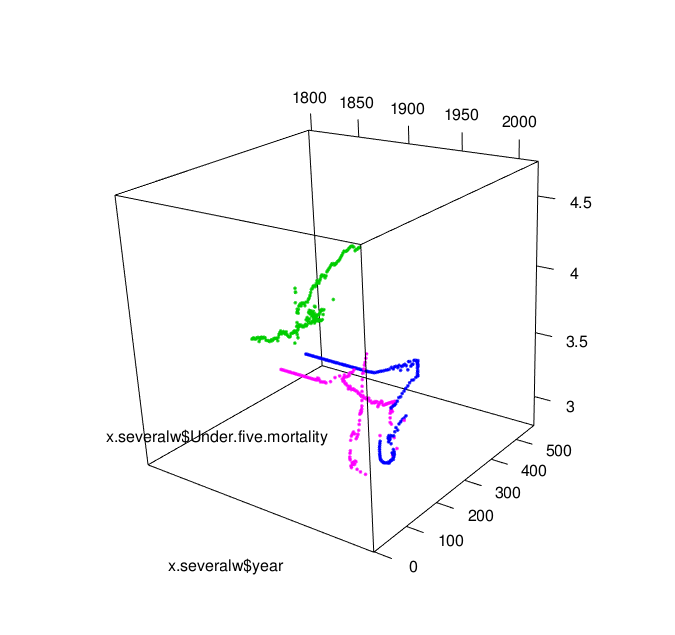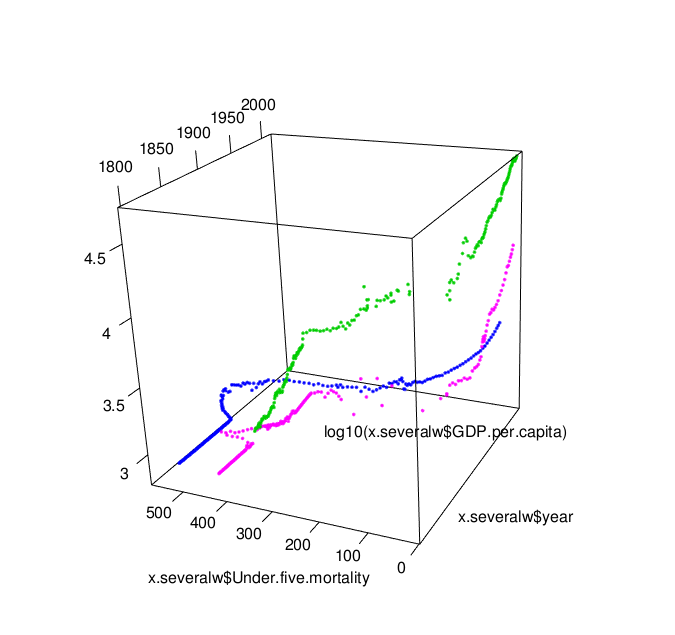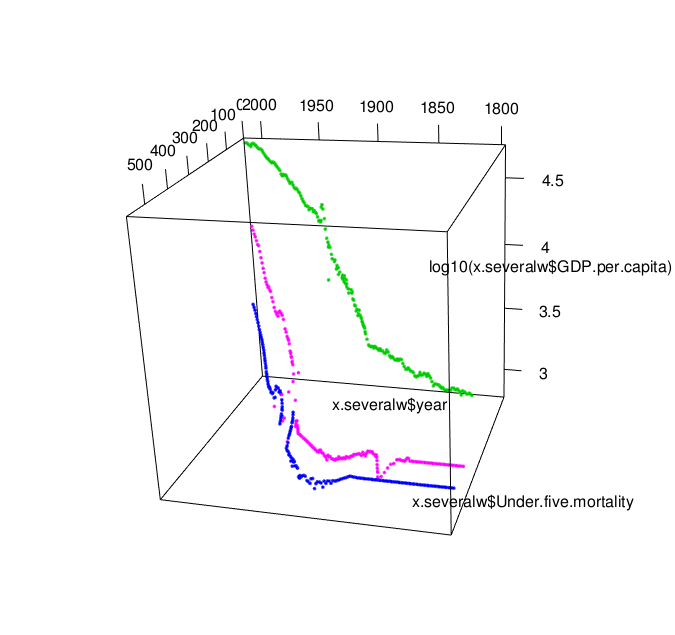
From playing with docker over the last few weeks, I think it’s worth pursuing as a technology for deploying educational software to online and distance education students, not least because it offers the possibility of using containers as app runners than can run an app on your own desktop, or via the cloud.
The command line is probably something of a blocker to users who expect GUI tools, such as a one-click graphical installer, or double click to start an app, so I had a quick scout round for graphical user interfaces in and around the docker ecosystem.
I chose the following apps because they are directed more at the end user – launching prebuilt apps, an putting together simple app compositions. There are some GUI tools aimed at devops folk to help with monitoring clusters and running containers, but that’s out of scope for me at the moment…
1. Kitematic
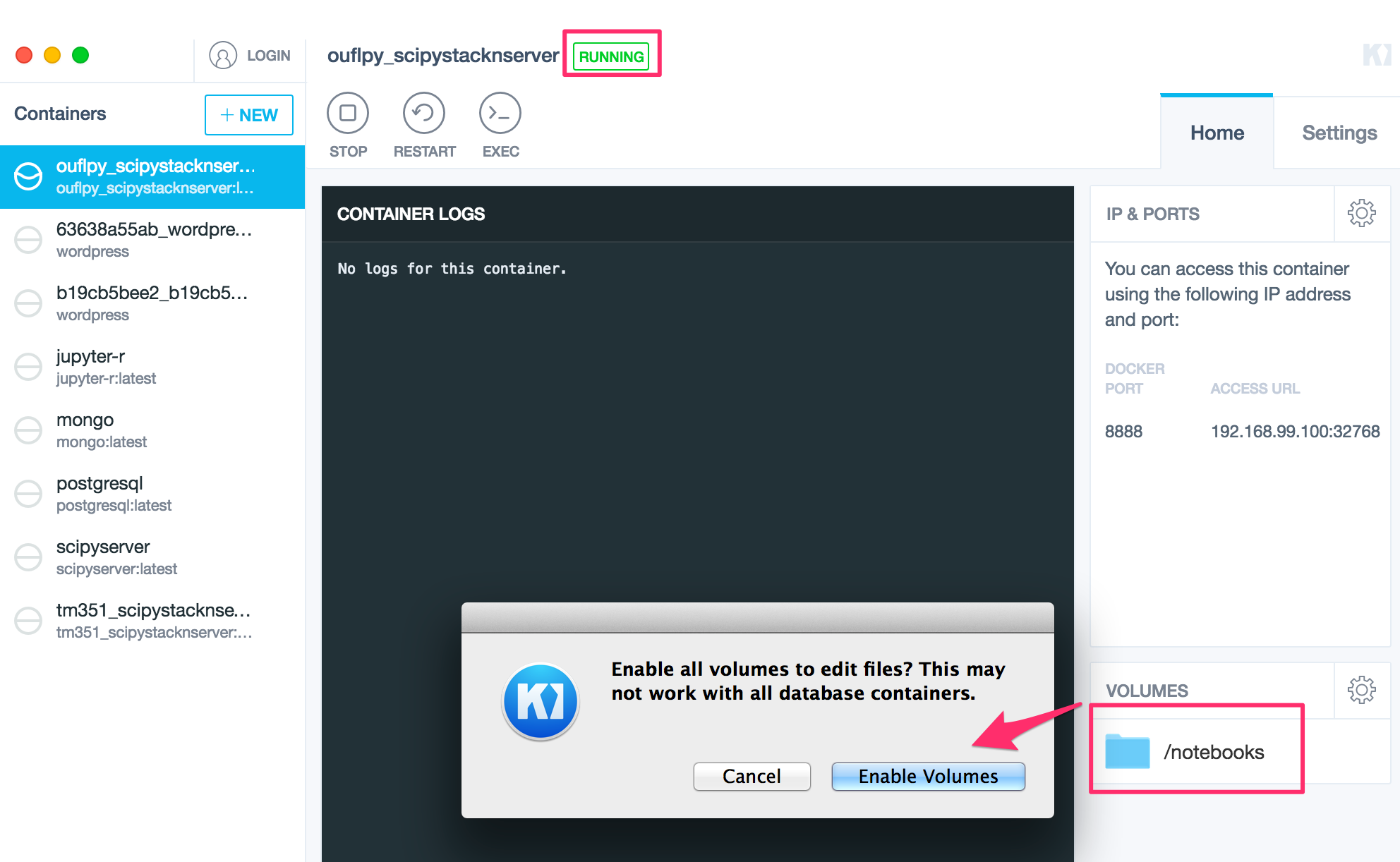
Kitematic is a desktop app (Mac and Windows) that makes it one-click easy to download images from docker hub and run associated containers within a local docker VM (currently running via boot2docker?).
I’ve blogged about Kitematic several times, but to briefly summarise: Kitematic allows you to launch and configure individual containers as well as providing easy access to a boot2docker command line (which can be used to run docker-compose scripts, for example). Simply locate an image on the public docker hub, download it and fire up an associated container.
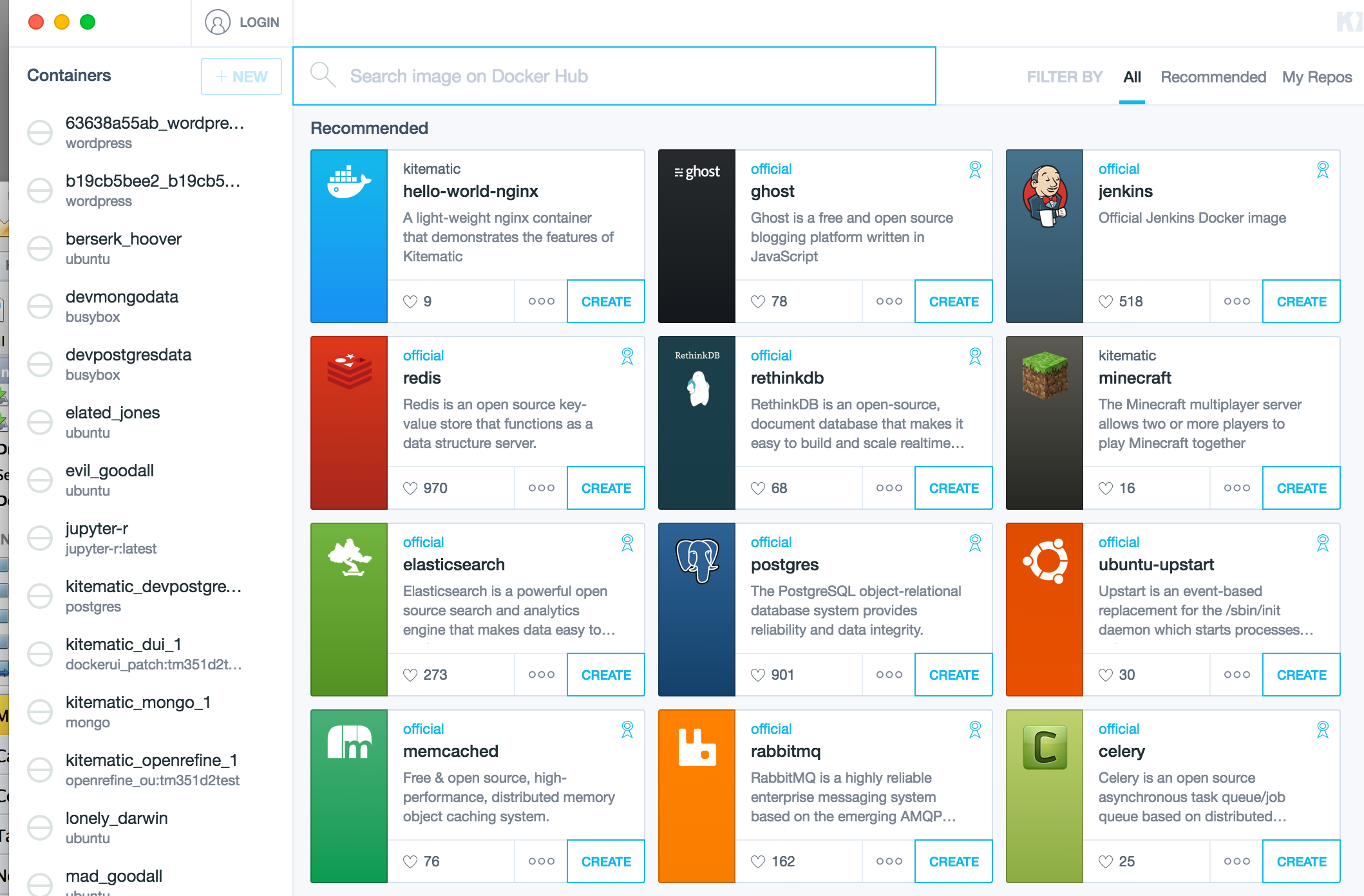
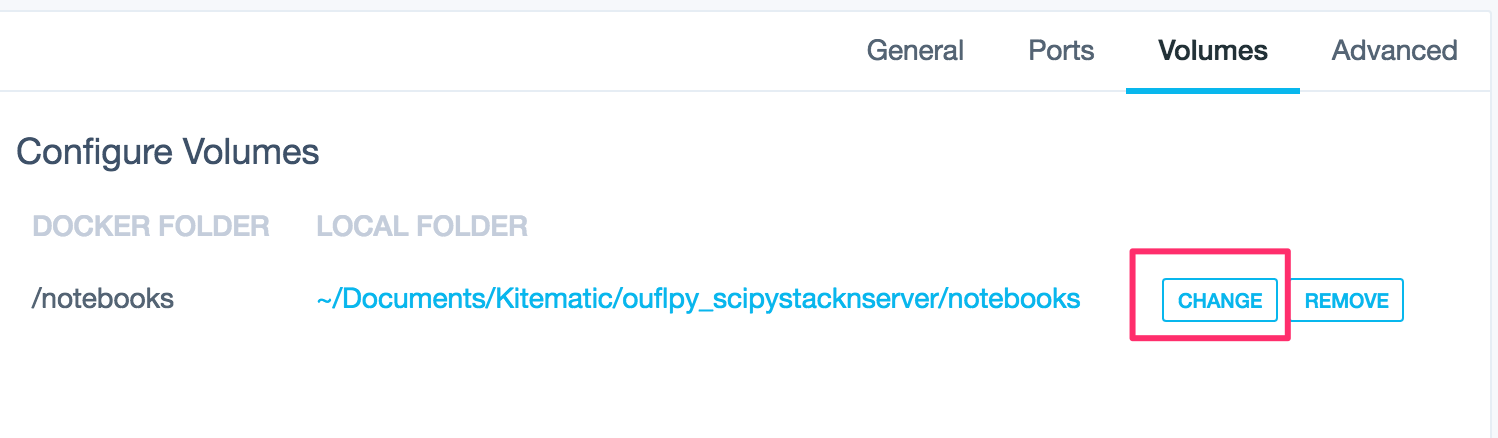
Where a mount point is defined to allow sharing between the container and the host, you can simply select the desktop folder you want to mount into the container.
At the moment, Kitematic doesn’t seem to support docker-compose in a graphical way, or allow users to deploy containers to a remote host.
2. Panamax
panamax.io is a browser rendered graphical environment for pulling together image compositions, although it currently needs to be started from the command line. Once the application is up and running, you can search for images or templates:

Trying to install it June 2107 using homebrew on a Mac, and it seems to have fallen out of maintenance…
Templates seem to correspond to fig/docker compose like assemblages, with panamax providing an environment for running pre-existing ones or putting together new ones. I think the panamax folk ran a competition some time ago to try to encourage folk to submit public templates, but that doesn’t seem to have gained much traction.

Panamax supports deployment locally or to a remote web host.

When I first came across docker, I found panamax really exciting becuase of the way it provided support for linking containers. Now I just wish Kitematic would offer some graphical support for docker compose that would let me drag different images into a canvas, create a container placeholder each time I do, and then wire the containers together. Underneath, it’d just build a docker compose file.
The public project files is useful – it’d be great to see more sharing of general useful docker-compose scripts and asscociated quick-start tutorials (eg WordPress Quickstart With Docker).
3. Lorry.io
lorry.io is a graphical tool for building docker compose files, but doesn’t have the drag, drop and wire together features I’d like to see.
Lorry.io is used to be published by CenturyLink, who also published panamax, (lorry.io was the newer development, I think?) But it seems to have disappeared… there’s still a code repo for it, though, and a docker container exists (but no Dockerfile?). It also looks like the UI requires an API server – again, the code repo is still there… Not sure if there’s a docker-compose script somewhere that can links these together and provide a locally running installation?


Lorry.io lets you search specify your own images or build files, find images on dockerhub, and configure well-formed docker compose YAML scripts from auto-populated drop down menu selections which are sensitive to the current state of the configuration.
4. docker ui
docker.ui is a simple container app that provides an interface, via the browser, into a currently running docker VM. As such, it allows you to browse the installed images and the state of any containers.

Kitematic offers a similar sort of functionality in a slightly friendlier way. See additional screenshots here.
5a. tutum Docker Cloud
[Tutum was bought out by Docker, and rebranded as Docker Cloud.]
I’ve blogged about tutum.co a couple of times before – it was the first service that I could actually use to get containers running in the cloud: all I had to do was create a Digial Ocean account, pop some credit onto it, then I could link directly to it from tutum and launch containers on Digital Ocean directly from the tutum online UI.

I’d love to see some of the cloud deployment aspects of tutum make it into Kitematic…
UPDATE: the pricing model adopted with the move to Docker Cloud is based on a fee-per-managed-node basis. The free tier offers one free managed node, but the management fee otherwise is at a similar rate to fee for actually running a small node on one of the managed services (Digital Ocean, AWS etc). So using Docker Cloud to manage your nodes could get expensive.
See also things like clusteriup.io
5b. Rancher
Rancher is an open source container management service that provides an alternative to Docker Cloud.
I haven’t evaluated this application yet.
To bootstrap, I guess you could launch a free managed node using Docker Cloud and use it to set up a Rancher running in a container on a Docker Cloud managed node. Then the cost of the management is the cost of running the server containing the Rancher container?
6. docker Compose UI
The docker compose UI looks as if it provides a browser based interface to manage deployed container compositions, akin to some of the dashboards provided by online hosts.
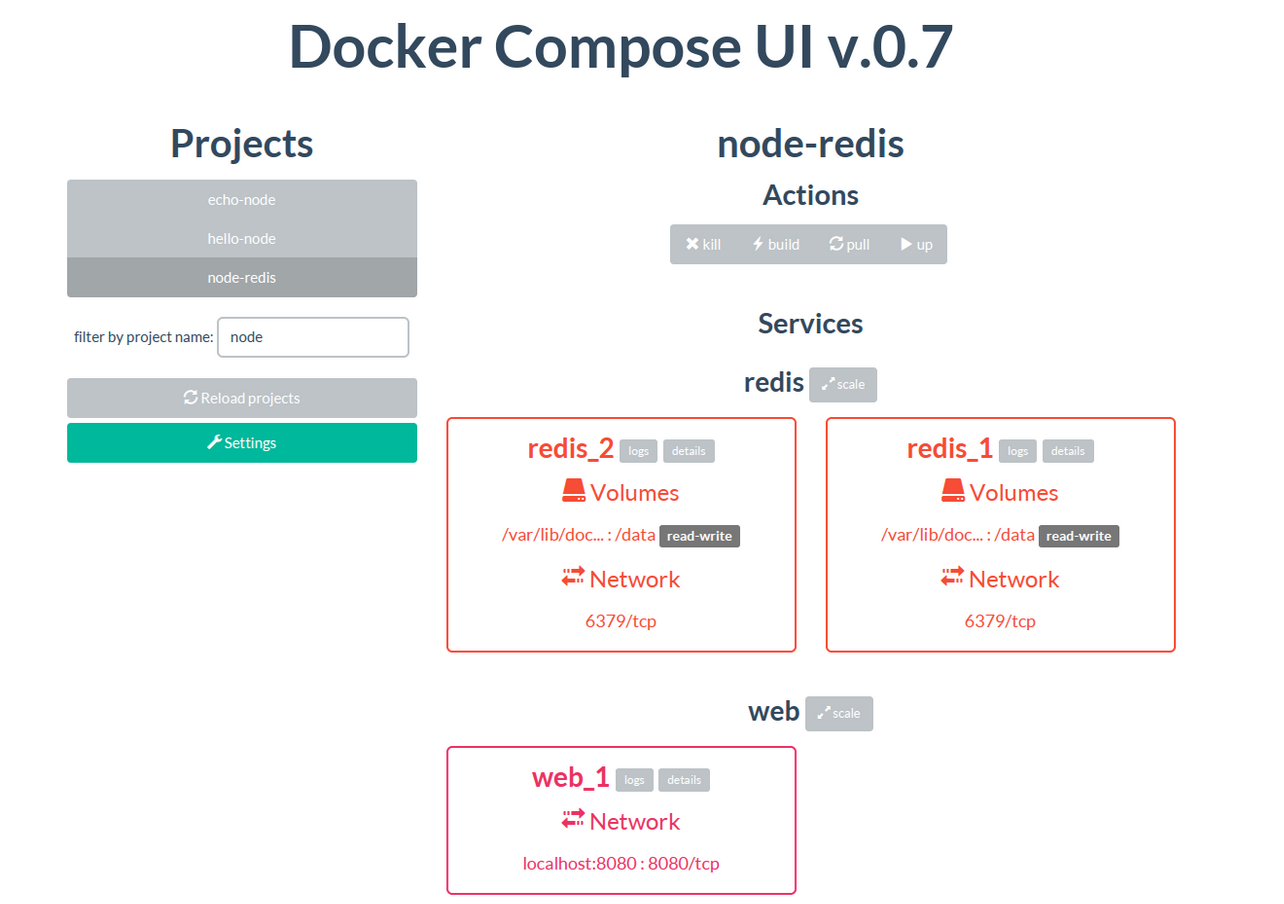
If you have a directory containing subdirectories each containing a docker-compose file, it’ll let you select and launch those compositions. Handy. And as of June 2017, still being maintained…
7. ImageLayers
Okay – I said I was going to avoid devops tools, but this is another example of a sort of thing that may be handy when trying to put a composition of several containers together because it might help identify layers that can be shared across different images.
imagelayers.io looks like it pokes through the Dockerfile of one or more containers and shows you the layers that get built.

I’m not sure if you can point it at a docker-compose file and let it automatically pull out the layers from identified sources (images, or build sources)?
PS here are the bonus apps since this post was first written:
- docker image graph: display a graphical tree view of the layers in your current current images; a graphical browser based view lets you select and delete unwanted layers/images.
- Wercker Container Workflows: manage what happens to a container after it gets built; free plan available.