A handful of brief news-y items…
Netflix Polynote Notebooks
Netflix have announced a new notebook candidate, Polynote [code], capable of running polyglot notebooks (scala, Python, SQL) with fixed cell ordering, variable inspector and WYSIWYG text authoring.
At the moment you need to download and install it yourself (no official Docker container yet?) but from the currently incomplete installation docs, it looks like there may be other routes on the way…
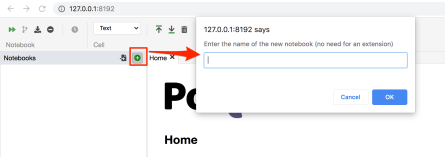
The UI is clean, and whilst perhaps slightly more cluttered than vanilla Jupyter notebooks it’s easier on the eye (to my mind) than JupyterLab.
Cells are code cells or text cells, the text cells offering a WYSIWYG editor view:
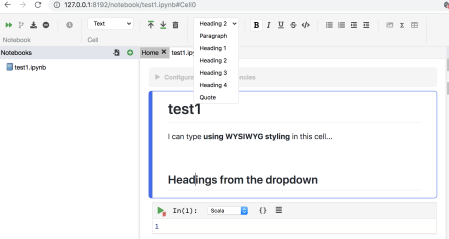
One of the things I note is the filetype: .ipynb.
Code cells are sensitive to syntax, with a code completion prompt:
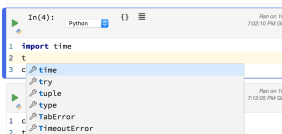
I really struggle with code complete. I can’t write import pandas as pd RETURN because that renders as import pandas as pandas. Instead I have to enter import pandas as pd ESC RETURN.
Running cells are indicated with a green sidebar to the cell (you can get a similar effect in Jupyter notebooks with the multi-outputs extension):
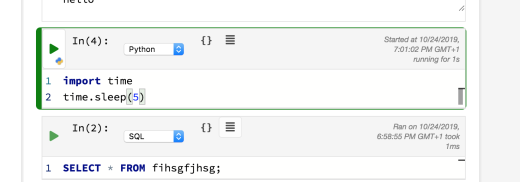
I couldn’t see how to connect to a SQL database, nor did I seem to get an error from running a presumably badly formed SQL query?
The execution model is supposed to enforce linear execution, but I could insert a cell after and unrun cell and get an error from it (so the execution model is not run all cells above either literally, or based on analysis of the programme abstract syntax tree?)
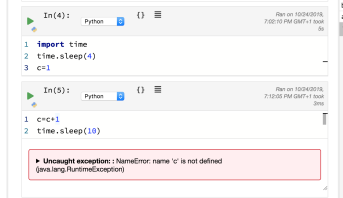
There is a variable inspector, although rather than showing or previewing cell state, you just get a listing of variables and then need to click through to view the value:
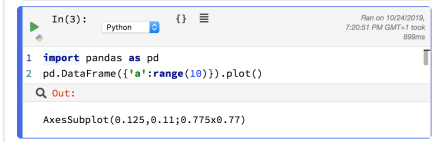
I couldn’t see how to render a matplotibl plot:
The IPython magic used in Jupyter notebooks throws an error, for example:
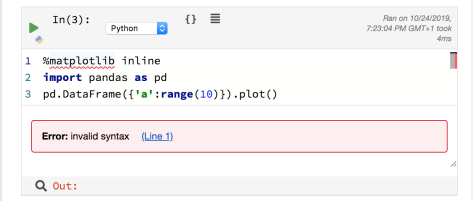
This did make me realise that cell lines are line numbered on one side and there’s a highlight shown on the other side which line errored. I couldn’t seem to click through to raise a more detailed error trace though?
On the topic of charts, if you have a Vega chart spec, you can paste that into a Vega spec type code cell and it will render the chart when you run the cell:
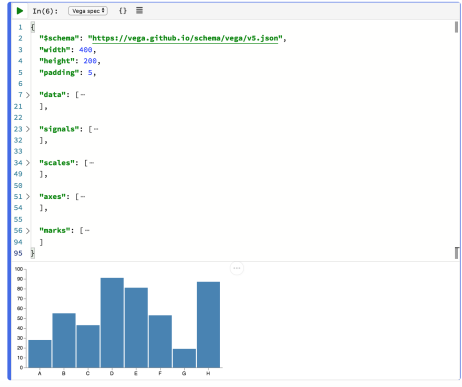
The developers also seem to be engaging with the “open” thing…
Take it for a spin today by heading over to our website or directly to the code and let us know what you think! Take a look at our currently open issues and to see what we’re planning, and, of course, PRs are always welcome!
Streamlit.io
Streamlit.io is another new not-really-a-notebook alternative, pip installable and locally runnable. The model appears to be that you create a Python file and run the streamlit server against that file. Trying to print("Hello World") doesn’t appear to have any effect — so that’s a black mark as far as I’n concerned! — but the display is otherwise very clean.
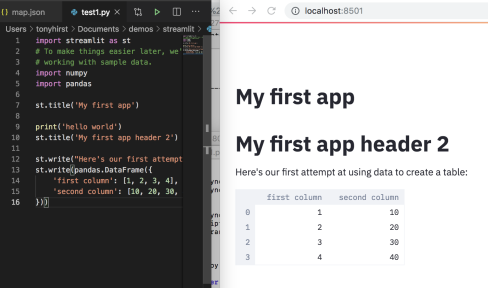
Hovering top right will raise the context menu (if it’s timed-out itself closed) showing if the source file has recently been saved and not rerun, or allowing you to always rerun the execution each time the file is saved.
I’m not sure if there’s any cacheing of steps that are slow to run if associated code hasn’t changed up to that point in a newly saved file.
Ah, it looks there is…
… and the docs go into further detail, with the use of decorators to support cacheing the output of particular functions.
I need to play with this a bit more, but it looks to me like it’d make for a really interesting VS Code extension. It also has the feel of Scripted Forms, as was, (a range of widgets are available in streamlit as UI components), and R’s Shiny application framework. It also feels like something I guess you could do in Jupyterlab, perhaps with a bit of Jupytext wiring.
In a similar vein, a package called Handout also appeared a few weeks ago, offering the promise of “[t]urn[ing] Python scripts into handouts with Markdown comments and inline figures”. I didnlt spot it in the streamlit UI, but it’d be useful to be able to save or export the rendered streamlit document eg as an HTML file, or even as an ipynb notebook, with run cells, rather than having to save it via the browser save menu?
Wolfram Notebooks
Wolfram have just announced their new, “free” Wolfram Notebooks service, the next step in the evolution of Wolfram Cloud (announcement review], I guess? (I scare-quote “free because, well, Wolfram; you’d also need to carefully think about the “open” and “portable” aspects…
*Actually, I did try to have a play, but I went to the various sites labelled as “Wolfram Notebooks” and I couldn’t actually find a 1-click get started (at all, let alone, for “free”) link button anywhere obvious?
Ah… here we go:
[W]e’ve set it up so that anyone can make their own copy of a published notebook, and start using it; all they need is a (free) Cloud Basic account. And people with Cloud Basic accounts can even publish their own notebooks in the cloud, though if they want to store them long term they’ll have to upgrade their account.







 The Select SQL temporarily pops the data into a SQLite database (I’m guessing….) and lets you then run SQL queries on it. One thing perhaps lacking from the import options is an ‘import from SQL’ option (OpenRefine has recently added
The Select SQL temporarily pops the data into a SQLite database (I’m guessing….) and lets you then run SQL queries on it. One thing perhaps lacking from the import options is an ‘import from SQL’ option (OpenRefine has recently added 



