Just over a year ago, I posted a series of posts (starting here) where I finally got round to hacking together a JupyterLab (v3.x) version of OUr empinken notebook extension that lets you colour individual Jupyter notebook cells from notebook toolbar button. I’m increasingly not a developer, even more so than I never was, so when the extension inevitably failed to work in JupyterLab v. 4, I was faced with having to repeat the painful experience again.
Anyway…
Here are some fragmentary notes getting a version of the extension working in v4. At the moment, user settings are not supported. Hopefully, that will be a simple migration of code from the v3.x extension. Hopefully…
Repo branch relating to the below is here. Install as: pip install https://github.com/innovationOUtside/jupyterlab_empinken_extension/raw/jlv4/dist/jupyterlab_empinken_extension-0.4.0-py3-none-any.whl
Adding Buttons Notebook Toolbars
A toolbar-button example in the jupyterlab/extension-examples repo “shows” how to add buttons to the toolbar, for some definition of show. The README tells you where you can find an “example” of how to attach a custom defined command to a button, but to see how to add the simple base button, you need to try to figure out what files to edit, and how…

From what I could tell, there is a two step process.
In the schema/plugin.json file, add JSON definitions for what the buttons are and what commands they call:
{
"jupyter.lab.toolbars": {
"Notebook": [
{
"name": "empinken-activity",
"command": "ouseful-empinken:activity",
"label": "A"
},
{
"name": "empinken-learner",
"command": "ouseful-empinken:learner",
"label": "L"
},
{
"name": "empinken-solution",
"command": "ouseful-empinken:solution",
"label": "S"
},
{
"name": "empinken-tutor",
"command": "ouseful-empinken:tutor",
"label": "T"
}
]
},
"title": "jupyterlab_empinken_extension",
"description": "jupyterlab_empinken_extension settings.",
"type": "object",
"properties": {},
"additionalProperties": false
}
I think there may also be a priority value, or similar, for controlling where in the toolbar the button is described. I’m sure I saw an example somewhere for how to register and use and SVG image for the button, but I forget where, and I’m saving that actual battle for another day (or not; the letters work ok-ish, and I have better things to do…)
The jupyterlab_code_formatter uses an alternative approach, creating a ToolbarButton explicitly, as I did in the original empinken extension. So maybe there was an easier migration route. Whatever. A ToolbarButton example looks like it may be on the way…
I’m not sure about the other settings in the schema/plugin.json file. Things are working atm, and I don’t have the will to explore what happens if I remove them.
We define the command used by the button in the src/index.ts file. The id is built up from the same root as the title in the schema/plugin.json file — I don’t know if that’s a requirement? (I have so many possibly superstitious , possibly relevant beliefs about trying to wrangle anything to do with JupyterLab… And zero understanding. For example, is the :plugin part of the id a convention or a meaningful requirement?)
import {
JupyterFrontEnd,
JupyterFrontEndPlugin
} from '@jupyterlab/application';
/**
* The plugin registration information.
*/
const plugin: JupyterFrontEndPlugin<void> = {
id: 'jupyterlab_empinken_extension:plugin',
description:
'A JupyterLab extension adding a button to the Notebook toolbar.',
requires: [],
autoStart: true,
activate: (app: JupyterFrontEnd) => {
const { commands } = app;
const command = 'ouseful-empinken:activity';
// Add commands
commands.addCommand(command, {
label: 'Execute ouseful-empinken:activity Command',
caption: 'Execute ouseful-empinken:activity Command',
execute: () => {
console.log(`ouseful-empinken:activity has been called.`);
}
}
})
})
}
/**
* Export the plugin as default.
*/
export default plugin;
So I can generate buttons. The buttons are there to do two things relative to a selected code cell:
- toggle a tag in the cell metadata;
- add class to the notebook cell HTML.
Strictly speaking, the second requirement, adding the class, should probably be triggered from a signal that a cell’s metadata has been updated. That would mean if an appropriate tag is added to a cell by other means, such as the JupyterLab cell tag editor, the custom styling would follow. But I don’t know if such a signal exists. So I’m piling all the concerns together…
Because the same command, essentially, is applied with a few parameters for each button, I create a generic function then customise its application in particular commands:
const empinken_tags: string[] = ["activity", "learner", "solution", "tutor"];
const createEmpinkenCommand = (label: string, type: string) => {
//this works wrt metadata
const caption = `Execute empinken ${type} Command`;
return {
label,
caption,
execute: () => {
let activeCell = notebookTracker.activeCell;
//console.log(label, type, caption)
//console.log(activeCell)
const nodeclass = 'iou-' + type + "-node";
if ( activeCell !== null) {
let tagList = activeCell.model.getMetadata("tags") as string[] ?? [];
//console.log("cell metadata was", tagList, "; checking for", type);
if (tagList.includes(type)) {
// ...then remove it
const index = tagList.indexOf(type, 0);
if (index > -1) {
tagList.splice(index, 1);
}
activeCell.model.setMetadata("tags", tagList)
// Remove class
activeCell.node.classList.remove(nodeclass)
// cell.node.classList exists
} else {
// remove other tags
tagList = removeListMembers(empinken_tags, tagList)
empinken_tags.forEach((tag:string) => {
activeCell.node.classList.remove('iou-' + tag + "-node")
})
// add required tag
tagList.push(type)
activeCell.model.setMetadata("tags", tagList)
activeCell.node.classList.add(nodeclass)
}
//console.log("cell metadata now is", tagList);
}
}
};
};
// Generate the commands that are registered for each button
empinken_tags.forEach((tag:string) => {
commands.addCommand('ouseful-empinken:'+tag,
createEmpinkenCommand(tag.charAt(0).toUpperCase(),
tag));
})
The notebooktracker is defined as part of the app activation:
import { INotebookTracker } from '@jupyterlab/notebook';
const plugin: JupyterFrontEndPlugin<void> = {
id: 'jupyterlab_empinken_extension:plugin',
description:
'A JupyterLab extension adding a button to the Notebook toolbar.',
requires: [INotebookTracker],
autoStart: true,
activate: (app: JupyterFrontEnd, notebookTracker: INotebookTracker) => {
...
As it stands, the app now publishes buttons to the notebook toolbar. Clicking a button toggles notebook metadata tag state and HTML style on a selected cell.
The next thing is to style cells when a notebook is rendered. In JupyerLab 3.5, a fullyrendered signal fired that could be used to detect a rendered notebook and pass the notebook reference. The original extension then added another pass of styling to colour appropriately tagged cells. The fullyrendered signal isn’t in 4.x, perhaps because notebooks are more intelligently rendered now, but I couldn’t find a signal that says when a notebook has been opened.
A call for help on the Jupyter discourse group about how to grab a list of open notebook references and then iterate through the cells brought a suggestion from Luke Anger to use the labShell.currentChanged signal:
import { LabShell } from '@jupyterlab/application';
...
const labShell = app.shell as LabShell;
labShell.currentChanged.connect(() => {
const notebook = app.shell.currentWidget as NotebookPanel;
const cellList = notebook.content.model.cells;
...
}
I’d previously tried using an event on the notebooktracker, but had given up because I couldn’t seem to get a list of anything other than the first cell:
notebookTracker.currentChanged.connect((tracker, panel) => {
if (!panel) {
return;
}
...
I had the same issue following Luke’s suggestion, but he then suggested it might be a race , and to wait awhile:
const labShell = app.shell as LabShell;
labShell.currentChanged.connect(() => {
const notebook = app.shell.currentWidget as NotebookPanel;
if (notebook) {
notebook.revealed.then(() => {
...
Luke had also suggested grabbing the list of cells from the notebook as notebook.content.model.cells. This does give a list of cells, but no access to the node object on a cell, so instead I went into via the rendered cells (notebook.content.widgets), which still give access to the cell metadata. (I guess at this point I should be thankful that changes to the cell widget metadata also seem to be mirrored on the cell model.)
const labShell = app.shell as LabShell;
labShell.currentChanged.connect(() => {
const notebook = app.shell.currentWidget as NotebookPanel;
if (notebook) {
notebook.revealed.then(() => {
notebook.content.widgets?.forEach(cell=>{
const tagList = cell.model.getMetadata('tags') ?? [];
//console.log("cell metadata",tagList)
tagList.forEach((tag:string) => {
if (empinken_tags.includes(tag)) {
//console.log("hit",tag)
cell.node?.classList.add('iou-'+tag+'-node');
}
})
})
})
}
});
Thus far, it all seems to work okay in JupyterLab 4.x (and breaks in JupyterLab 3.x); but that’s probably okay, and I just have to remember different versions of the extension are required for JupyterLab 3/4.
Still to do: I’d like to add user settings back in, so users can change the colour applied to each tag. Hopefully, this is just a straightforward migration of the 3.x settings code. It’d be nice to be able to colour cells if appropriate tags are added by other means, and it’d be nice to have icons in the buttons. But I found it painful enough getting as far as the above, and I don’t really want to make myself tired-frustrated-and-angry again…
PS for an example of manually creating a button, see https://github.com/kondratyevd/toolbar-button


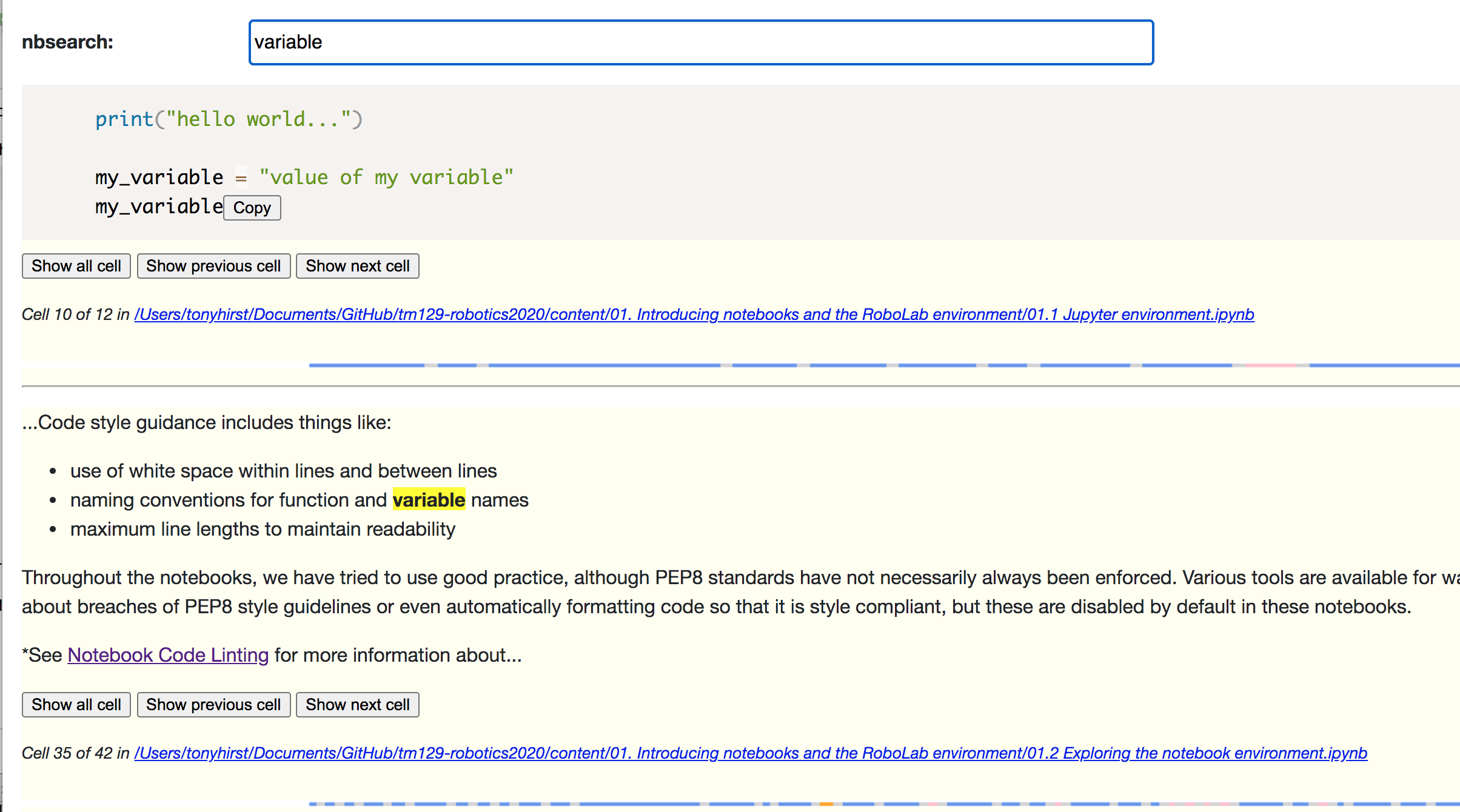
































 So… no more than half an hour from a zero start (I was actually tinkering whilst on a call, so only half paying attention too…).
So… no more than half an hour from a zero start (I was actually tinkering whilst on a call, so only half paying attention too…).



























