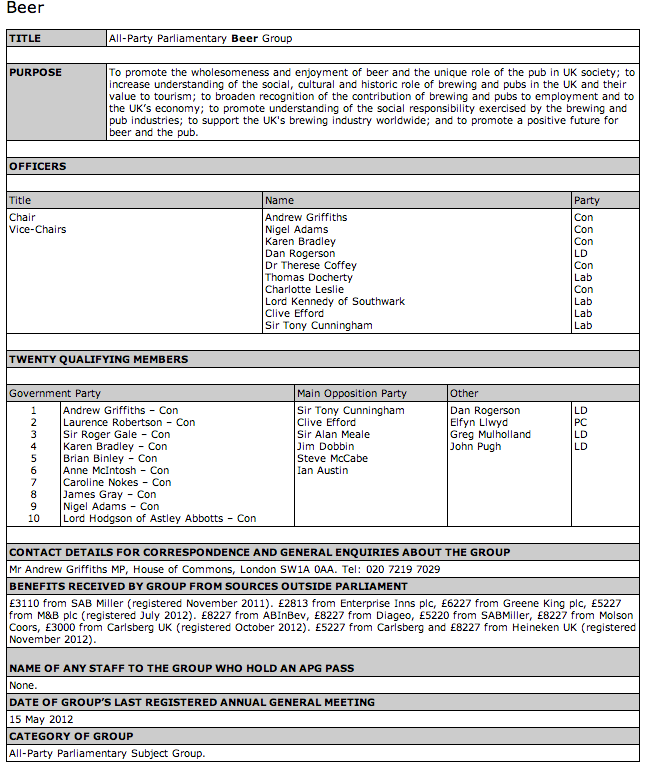
Whilst looking at the apparently conflicting results from a couple of recent polls by YouGov on press regulation (reviewed in a piece by me over on OpenLearn: Two can play at that game: When polls collide in support of a package on the OU/BBC co-produced Radio 4 programme, More Or Less), my eye was also drawn to the different ways in which the survey results were presented graphically.
The polls were commissioned by The Sun newspaper on the one hand, and the Media Standards Trust/Hacked Off on the other. If you look at the poll data (The Sun/YouGov [PDF] and Media Standards Trust/YouGov [PDF] respectively), you’ll see that it’s reported in a standard format. (I couldn’t find actual data releases, but the survey reports look as if they are generated in a templated way, so getting the core of a generic scraper together for them shouldn’t be too difficult…) But how was that represented to readers (text based headlines and commentary aside?
Here are a couple of grabs from the Sun’s story (State-run watchdog ‘will gag free press’):

Pie-charts in 3D, with a tilt… gorgeous… erm, not… And the colour choice for the bar chart inner-column text is a bit low on contrast compared to the background, isn’t it?

It looks a bit like the writer took a photo of the print edition of the story on their phone, uploaded it and popped it into the story, doesn’t it?
I guess credit should be given for keeping the risk responses separate in the second image, when they could have just gone for the headline figures as pulled out in the YouGov report:

So what I’m wondering now is the extent to which a chart’s “theme” or style reflects the authority or formal weight we might ascribe to it, in much the same way as different fonts carry different associations? Anyone remember the slating that CERN got for using Comic Sans in their Higgs-Boson discovery announcement (eg here, here or here)?

Things could hardly have been more critical if they had used CrappyGraphs or an XKCD style chart generator (as for example described in Style your R charts like the Economist, Tableau … or XKCD ; or alternatively, XKCD-style for matplotlib).
 [XKCD]
[XKCD]
Oh, hang on a minute, it almost looks like they did!

Anyway – back to the polls. The Media Standards Trust reported on their poll using charts that had a more formal look about them:

The chart annotations are also rather clearer to read.
So what, if anything, do we learn from this? That maybe you need to think about chart style, in the same way you might consider your font selection. From the R charts like the Economist, Tableau … or XKCD post, we also see that some of the different applications we might use to generate charts have their own very distinctive, and recognisable, style (as do many Javascript charting libraries). A question therefore arises about the extent to which you should try to come up with your own distinctive (but still clear) style that fits the tone of your communication, as well as its context and in sympathy with any necessary branding or house styling.
PS with respect to the Sun’s copyright/syndication notice, and my use of the images above:

I haven’t approached the copyright holders seeking permission to reproduce the charts here, but I would argue that this piece is just working up to being research into the way numerical data is reported, as well as hinting at criticism and review. So there…
PPS As far as bad charts go, they may also be, misrepresentations and underhand attempts at persuasion, graphic style, are also possible, as SimplyStatistics describes: “The statisticians at Fox News use classic and novel graphical techniques to lead with data” [ The statisticians at Fox News use classic and novel graphical techniques to lead with data ] See also: OpenLearn – Cheating with Charts.